O Eclipse é um IDE (Integrated Development Environment, ou Ambiente de Desenvolvimento Integrado) extremamente poderoso e flexível, sendo o mais utilizado no mercado e para diversas finalidades: desenvolvimento Java, Android, C++, modelagem de processos, desenho de relatórios e assim por diante.
Utilizar um bom IDE é essencial para a produtividade, pois suas inúmeras ferramentas e funcionalidades farão a diferença no dia-a-dia na procura por defeitos, formatação e melhoraria do código, integração com sistemas SCM (Source Control Management ou Gerência de Configuração), como SVN, CVS, GIT, Mercurial ou Bazaar e muitas coisas.
Baixando o Eclipse
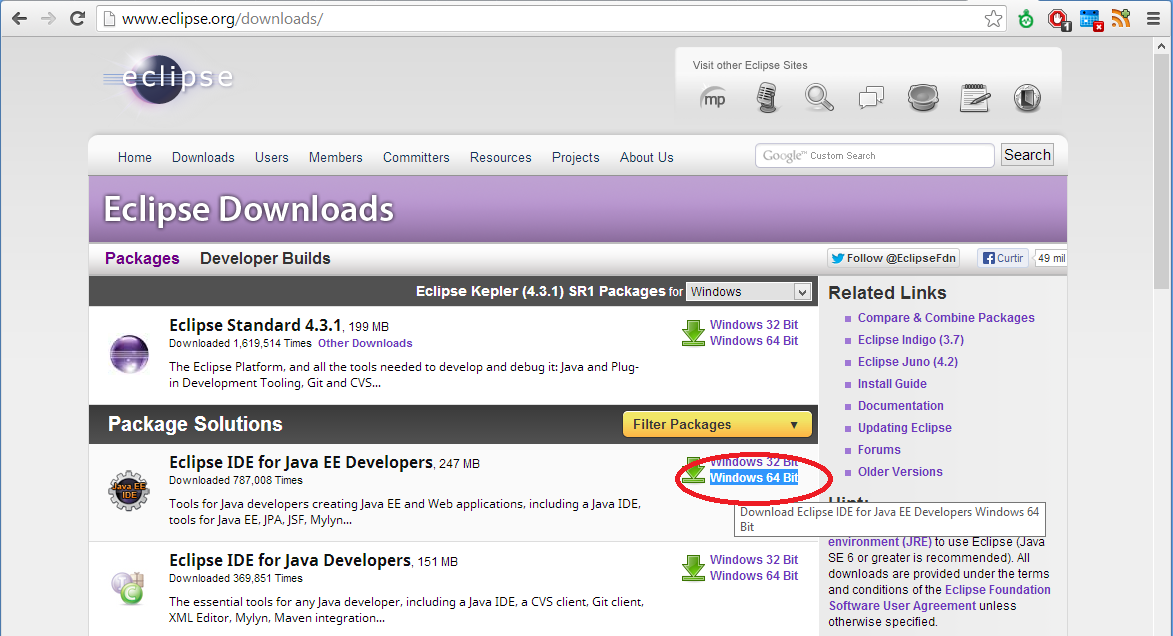
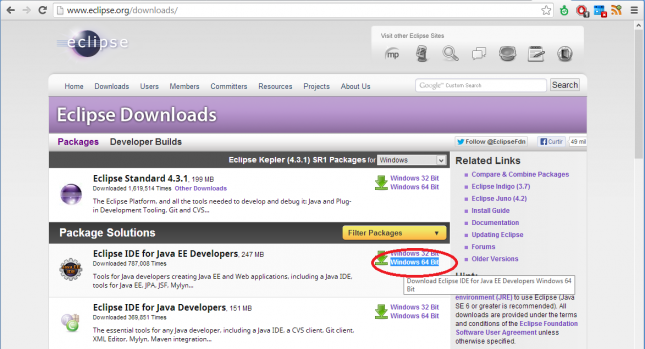
Acesse http://www.eclipse.org/downloads/ para baixar o Eclipse IDE for Java EE Developers. Escolha a versão correspondente ao seu sistema, que no meu caso é um Windows 64 bits. Veja a imagem abaixo:
Ao clicar no link, você será redirecionado para outra página onde poderá escolher um “espelho” (mirror), isto é, uma cópia do arquivo que esteja num servidor próximo de onde você mora. Clique na seta verde para efetivamente iniciar o download, conforme a imagem:

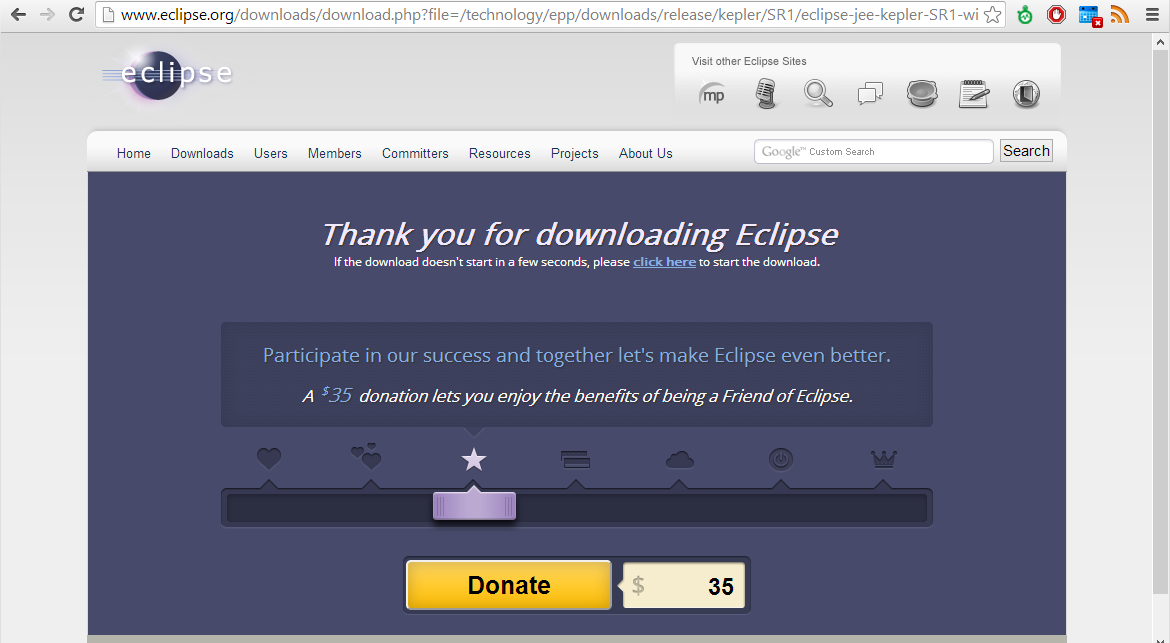
O download será iniciado e o navegador exibirá a seguinte página:
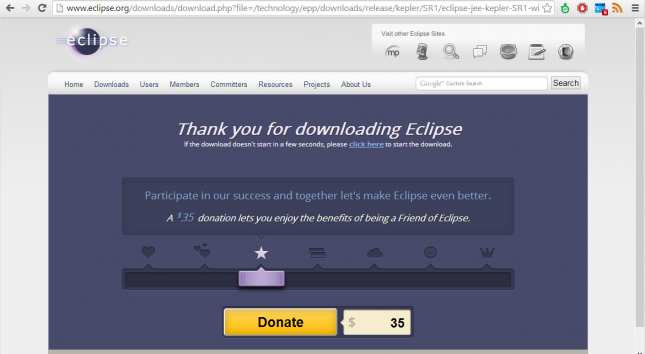
No futuro, considere contribuir para tornar o Eclipse ainda melhor. 😉
Instalando o Eclipse
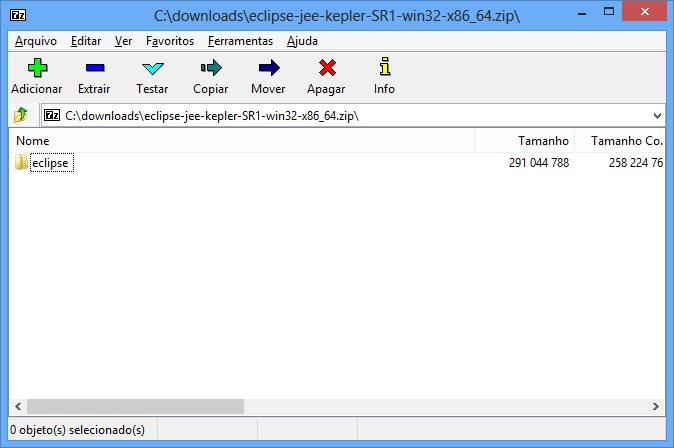
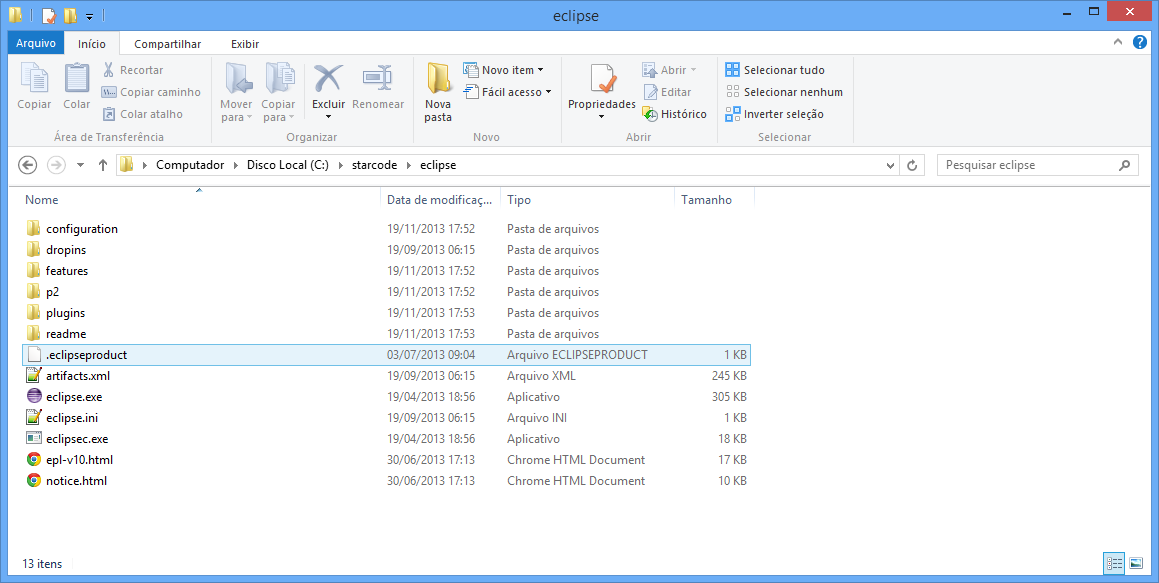
Neste e nos próximos tutoriais, o diretório c:\starcode será adotado como base para a instalação de programas e para armazenamento de arquivos. Caso queira, substitua “starcode” pelo nome da sua empresa, organização ou o que desejar, somente evite espaços em branco e acentos. Procure o arquivo baixado com o Eclipse e descompacte no diretório c:\starcode\eclipse, conforme as imagens abaixo:
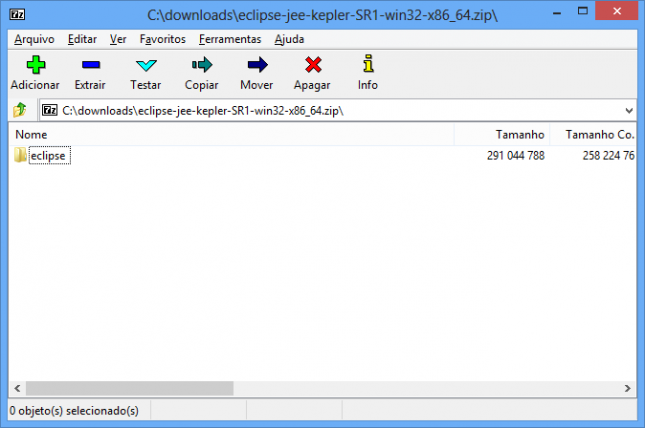
Neste exemplo, estou usando o 7-Zip. Abrindo o arquivo baixado, pressione F5 ou clique no menu Arquivo > Copiar Para.... Na caixa de diálogo, digite c:\starcode.
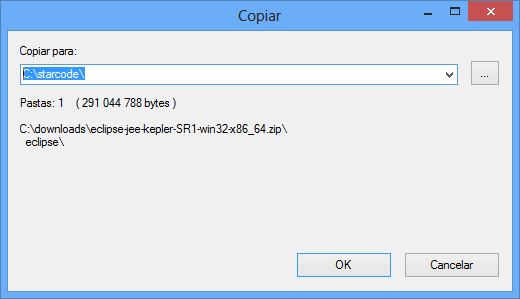
Confirme e verifique se o conteúdo do diretório c:\starcode\eclipse está conforme a imagem:
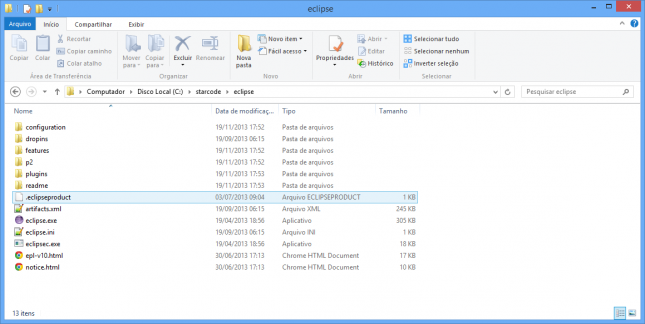
Configurando o Eclipse
Antes de executar o Eclipse, vamos ajustar alguns parâmetros de uso de memória para melhorar o desempenho geral de nosso IDE. Edite o arquivo eclipse.ini no seu editor de textos favorito (sugiro usar o Notepad++). O arquivo original deve conter algo assim:
-startup
plugins/org.eclipse.equinox.launcher_1.3.0.v20130327-1440.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.1.200.v20130807-1835
-product
org.eclipse.epp.package.jee.product
--launcher.defaultAction
openFile
--launcher.XXMaxPermSize
256M
-showsplash
org.eclipse.platform
--launcher.XXMaxPermSize
256m
--launcher.defaultAction
openFile
--launcher.appendVmargs
-vmargs
-Dosgi.requiredJavaVersion=1.6
-Xms40m
-Xmx512m
É importante entender o que estamos fazendo, pois este ajuste depende da configuração do computador onde o Eclipse será executado. Os seguintes parâmetros serão ajustados ou adicionados:
- X:MaxPermSize / launcher.XXMaxPermSize: este parâmetro define a quantidade máxima de memória permanente que o Java irá usar para armazenar informações sobre estrutura de classes (bytecode). A memória “permanente” irá limitar a quantidade de classes que podemos usar. Este parâmetro deve ser aumentado se você tiver muitos projetos com muitos jars diferentes. O parâmetro launcher.XXMaxPermSize serve para algumas versões do Eclipse, então vamos mantê-lo por questões de compatibilidade.
- XX:PermSize: iremos acrescentar este parâmetro para definir a quantidade inicial de memória permanente que o Java irá alocar. Se o valor deste parâmetro for muito pequeno, o desempenho do aplicativo será prejudicado em alguns momentos, pois o Java terá que interromper a execução para alocar mais memória frequentemente.
- Xmx: define a quantidade máxima de memória dinâmica que o java irá alocar para instâncias de objetos e variáveis que são alocados e desalocados a qualquer momento.
- Xms: define a quantidade inicial de memória dinâmica.
O valor padrão do parâmetro XXMaxPermSize está razoável, mas acrescentaremos o XX:PermSize para melhorar o tempo de inicialização do Eclipse, de modo que ele não tenha que ficar alocando memória muitas vezes.
Já os valores de Xmx e Xms podem ser ajustados dependendo da configuração do seu computador. Como eu trabalho com vários projetos e tenho 8 Gibabytes de memória RAM, irei colocar um valor máximo de 2 Gigabytes de memória no Xmx e um valor inicial de 512 Megabytes no Xms.
O arquivo de configuração final ficou assim:
-startup
plugins/org.eclipse.equinox.launcher_1.3.0.v20130327-1440.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.1.200.v20130807-1835
-product
org.eclipse.epp.package.jee.product
--launcher.defaultAction
openFile
--launcher.XXMaxPermSize
256M
-showsplash
org.eclipse.platform
--launcher.XXMaxPermSize
256m
--launcher.defaultAction
openFile
--launcher.appendVmargs
-vmargs
-Dosgi.requiredJavaVersion=1.6
-Xms512m
-Xmx2G
-XX:PermSize=128m
-XX:MaxPermSize=256m
Executando o Eclipse
Execute o arquivo eclipse.exe. Você verá por algum tempo o splash a seguir:

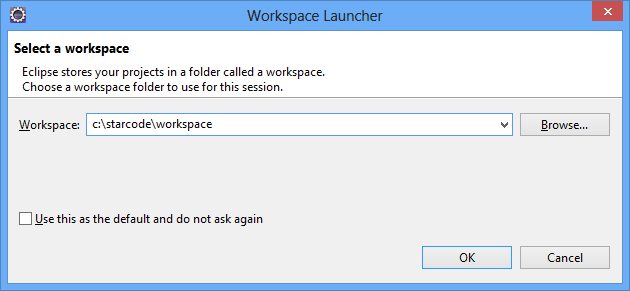
Depois você será saudado com a tela de seleção de Workspace (Workspace Launcher). Um Workspace consiste num local (diretório) onde ficarão as suas configurações do Eclipse e pode também conter vários projetos (embora não seja necessário que os projetos estejam no mesmo local). Isso significa que, com uma única instalação do Eclipse, você pode criar vários Workspaces em diferentes diretórios e cada um terá suas configurações e projetos específicos e independentes. O Eclipse pode ser executado mais de uma vez e assim você pode trabalhar em múltiplos Workspaces simultaneamente, porém não é possível abrir o mesmo Workspace em duas instâncias do Eclipse.
Digite o valor c:\starcode\workspace, conforme a imagem abaixo, para criar um novo Workspace no diretório informado e clique em OK.
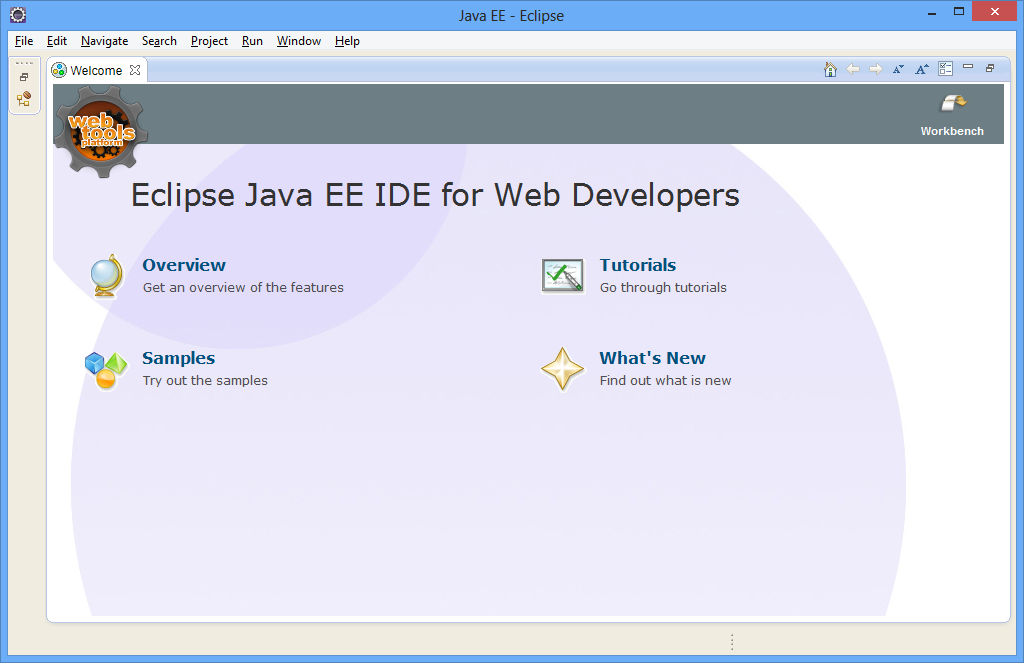
Aguarde alguns instantes e finalmente o IDE irá aparecer, exibindo a tela de boas-vindas (Welcome):
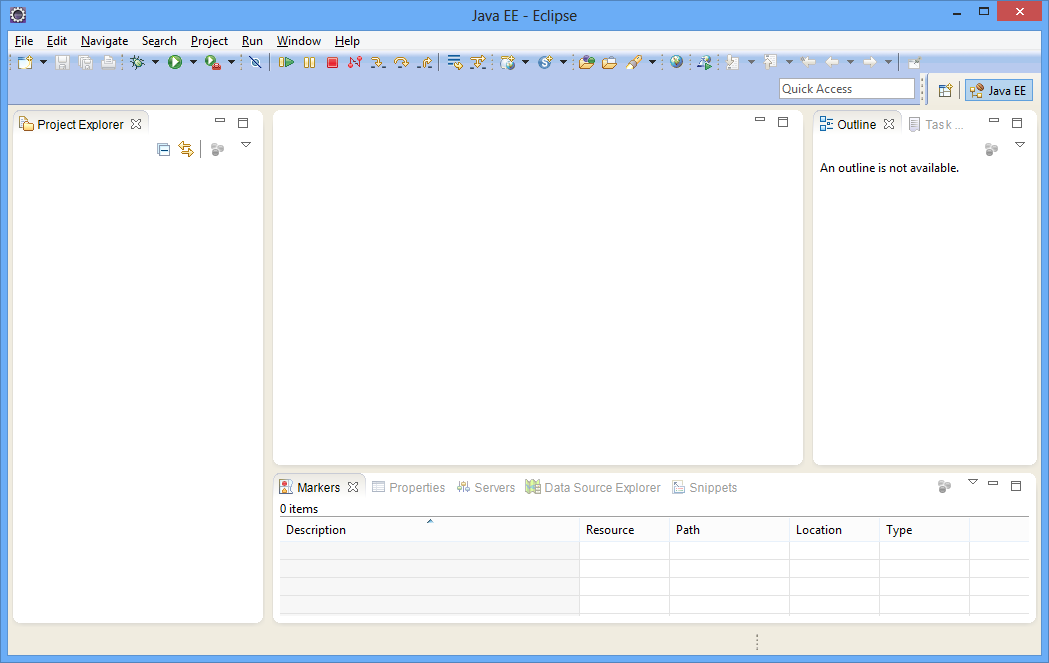
Feche a tela de boas-vindas clicando no link Workbench, no canto superior direito. Neste momento a tela de trabalho do Eclipse será apresentada:
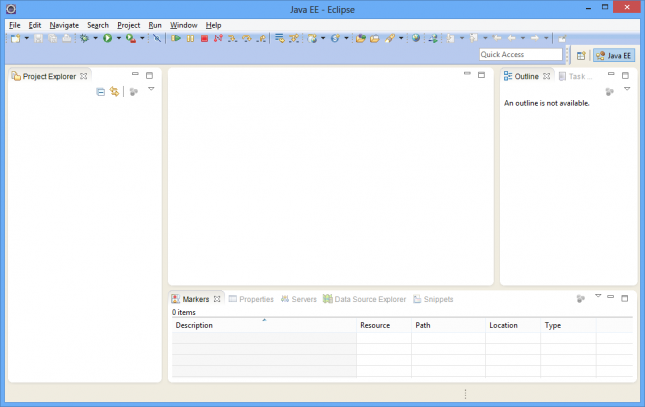
Configurando o Workspace
Vamos realizar algumas configurações básicas e visuais. A primeira é trocar a perspectiva de trabalho. O Eclipse é um IDE multifuncional e isso significa que ele lhe permite executar diversas atividades, por exemplo: codificar em Java, criar consultas a bancos de dados, depurar a execução do programa (debug), sincronizar os arquivos locais com um repositório remoto, etc. Certas atividades estão associadas a perspectivas, as quais contém os componentes (chamados de Views) adequados para a tarefa que você está realizando.
Clique no menu Window > Open perspective > Java. Note que que a janela mudou ligeiramente, conforme a imagem abaixo.
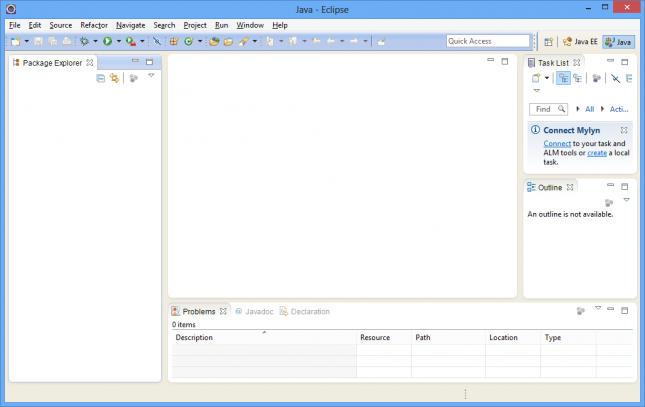
Vamos analisar rapidamente alguns componentes da tela:
- Menu principal (no topo da tela): acesso às funcionalidades atualmente disponíveis. Alguns menus podem mudar dependendo da perspectiva atualmente selecionada ou do arquivo atualmente sendo editado.
- Barra de ferramentas (abaixo do menu principal): os botões contém ações mais comuns e também podem mudar dependendo da perspectiva e do arquivo.
- Package Explorer (esquerda): view que lista os projetos e arquivos dos projetos.
- Problems (parte de baixo): view que exibe erros e alertas encontrados nos projetos.
- Tela central (em branco): editor onde serão abertos os arquivos.
Note ainda no canto superior direito a caixa Quick Access, onde você pode digitar qualquer coisa (configuração, nome de arquivo, etc.) e o Eclipse irá retornar os resultados rapidamente. À direita desta caixa estão listadas as perspectivas recentemente utilizadas, então você pode trocar facilmente a qualquer momento.
Irei fechar as views TaskList e Outline, pois não iremos utilizá-las neste momento.
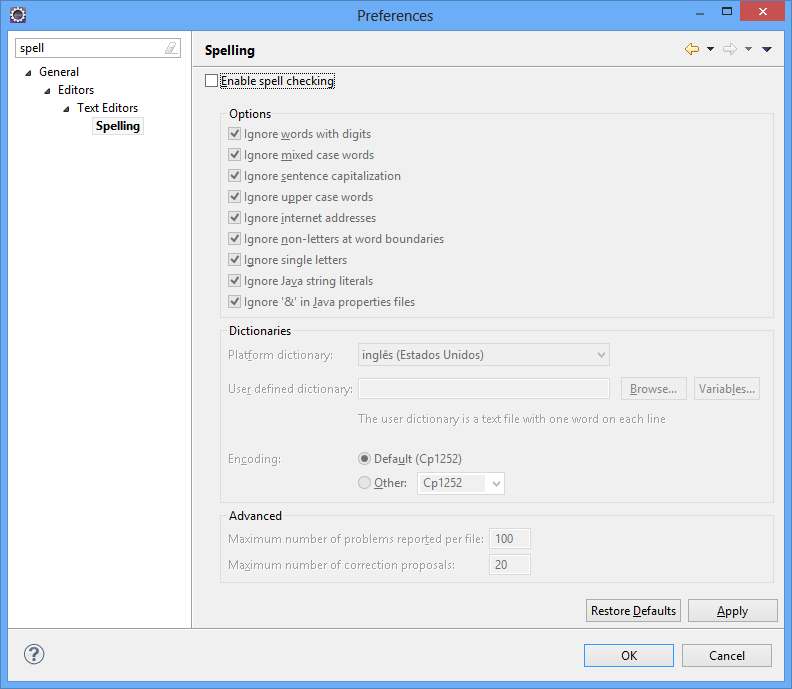
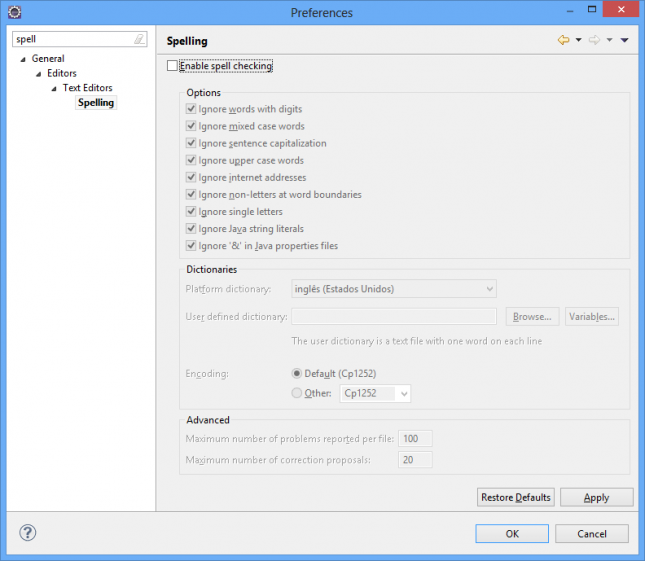
Vamos realizar também algumas configurações para otimizar nosso trabalho. A primeira é desligar o corretor ortográfico em Inglês, caso contrário tudo o que escrevermos em Português ficará sublinhado de vermelho. Acesse o menu Window > Preferences..., pesquise pela configuração Spelling e desmarque a opção principal, conforme a tela abaixo:
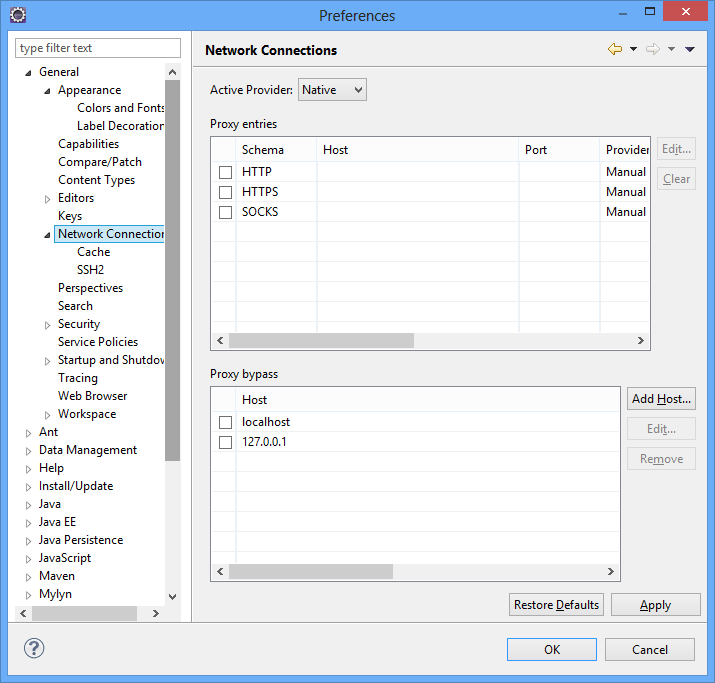
Caso esteja acessando a Internet sob um servidor Proxy, configure-o em Network Connection. Note que alguns plugins do Eclipse não funcionarão adequadamente mesmo com essas configurações de Proxy. Além disso, Proxies com NTLM não podem ser configurados através deste método. Verifique o tipo de Proxy que você possui e, se tiver dificuldades, serão necessárias soluções mais específicas que estão fora do escopo deste tutorial.
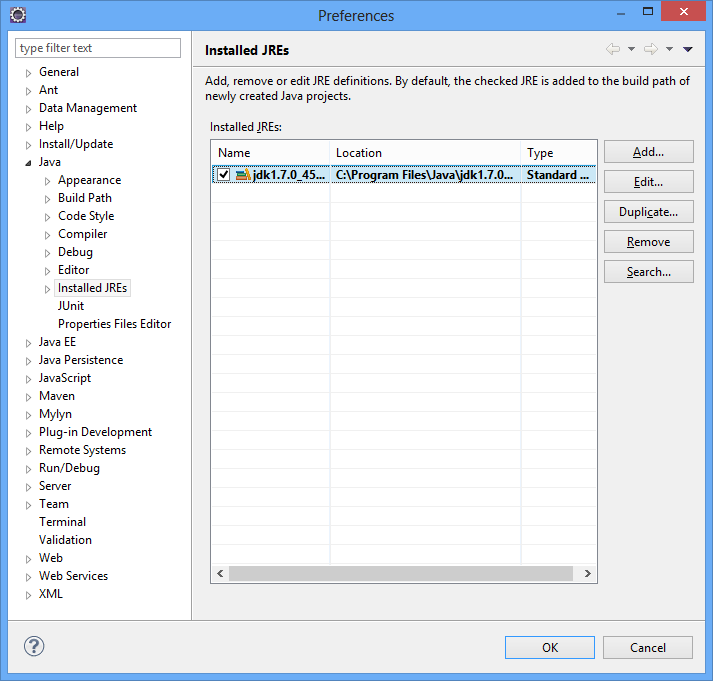
Se você tem um JDK devidamente instalado, o Eclipse deve tê-lo encontrado e adicionado automaticamente à sua configuração. Entretanto, verifique se está correto na configuração Installed JREs.
Após realizar as configurações acima, clique em OK.
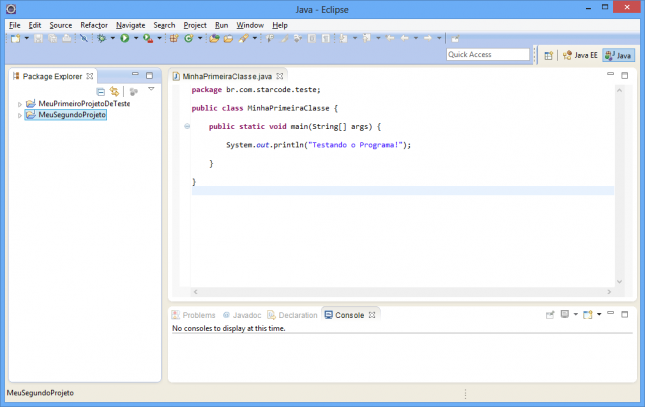
Criando um projeto para teste
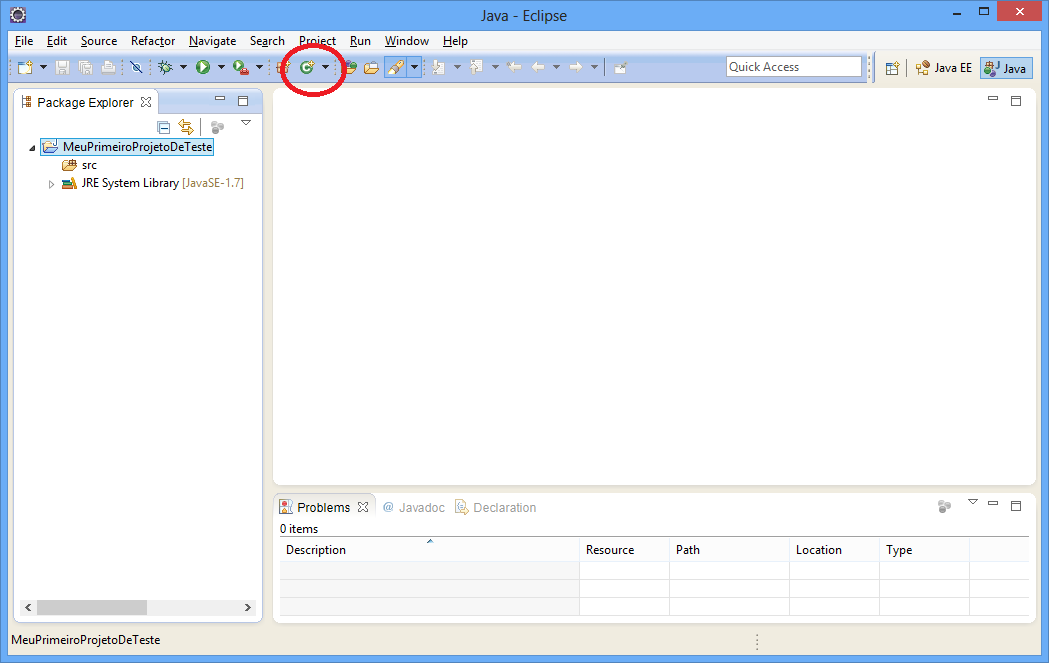
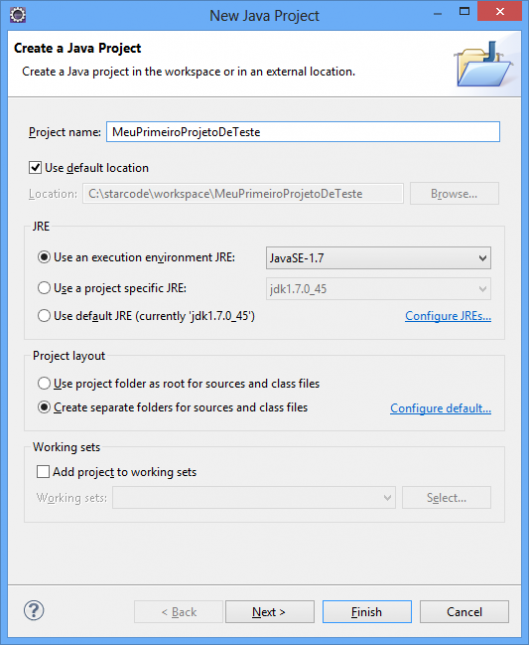
Vamos criar um projeto simples com o objetivo de verificar a instalação e permitir que você se acostume com o ambiente do Eclipse. Acesse o menu File > New > Java Project. Dê um nome ao projeto e clique em Finish.
A view Package Explorer irá exibir o novo projeto. Clique na seta à esquerda do nome para mostrar seu conteúdo.
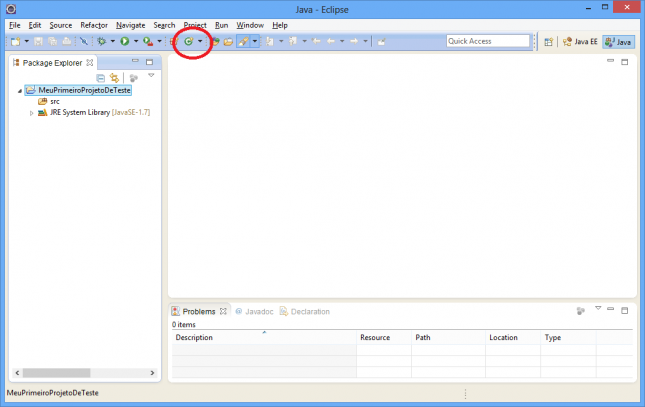
Vamos criar uma classe Java. Acesse File > New > Class ou simplesmente clique no botão indicado em vermelho na figura acima.
Na próxima tela, preencha o campo Package com o valor br.com.starcode.teste. O padrão para nomes de pacotes é usar sempre letras minúsculas, não usar caracteres especiais, números somente em situações especiais. Subpacotes são definidos usando o caractere de ponto final (.). Preencha também o campo Name com o nome da classe. Nomes de classes devem manter o padrão CamelCase, isto é, usa-se maiúsculas nas inicias das palavras, por exemplo “MinhaPrimeiraClasse”. Evite caracteres especiais e números. Marque a opção “public static void main(String[] args)” e clique em Finish para confirmar a criação da classe.
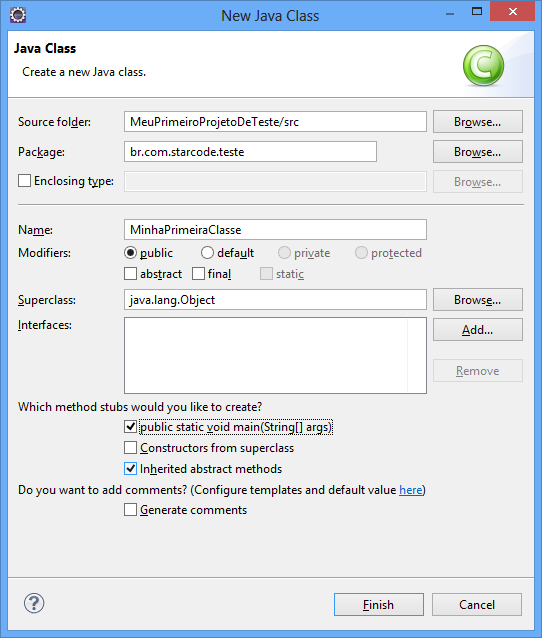
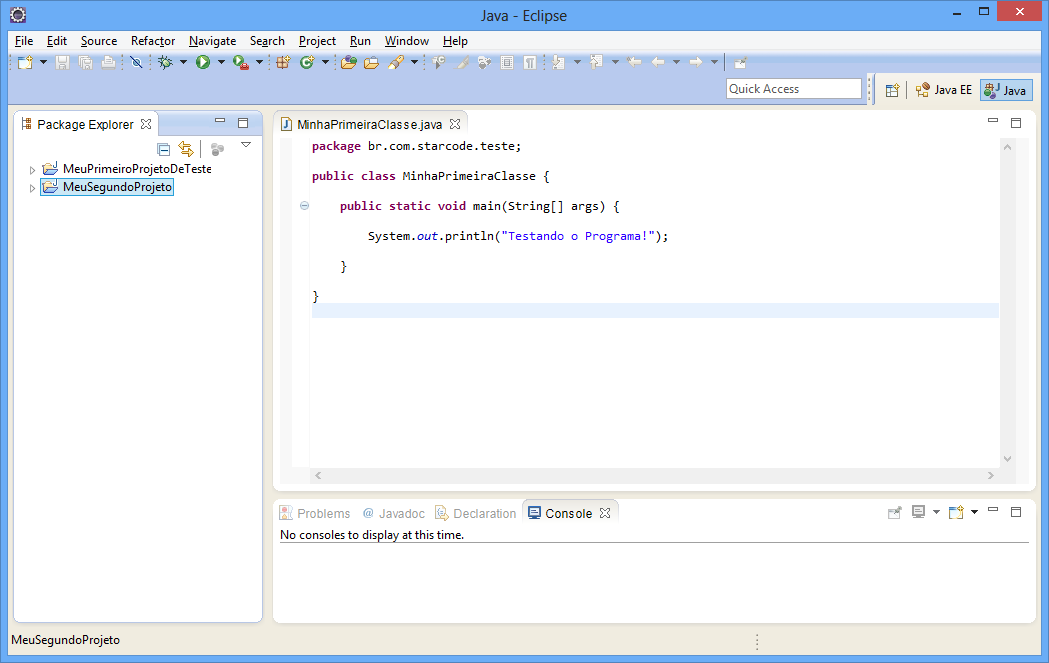
Veja como está a visualização:
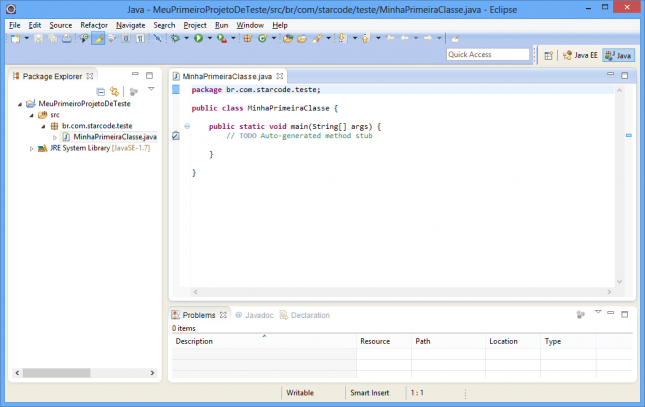
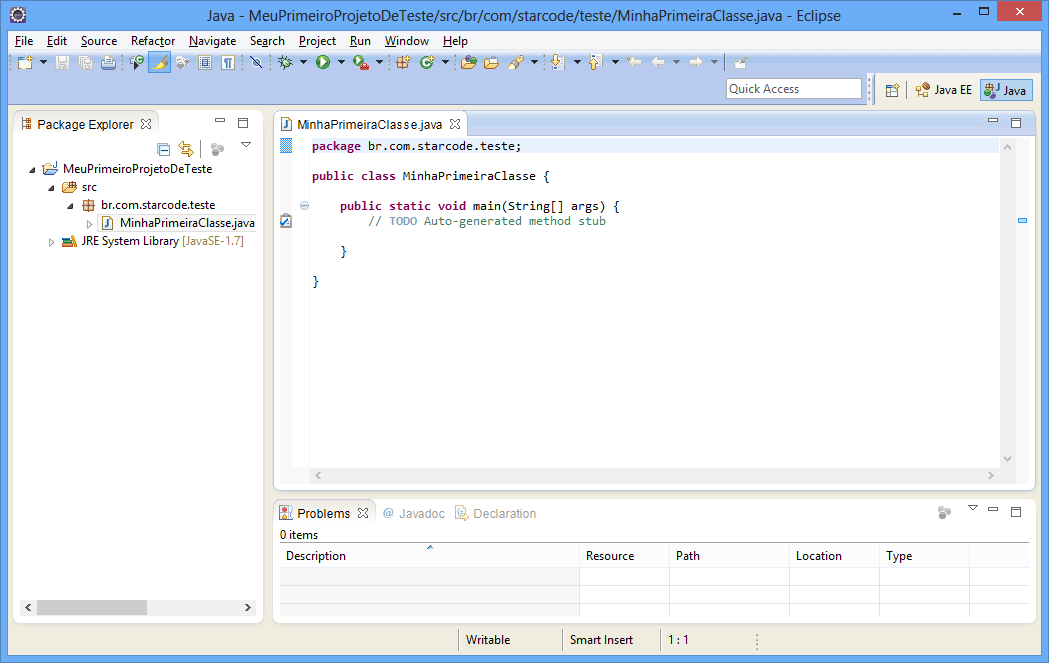
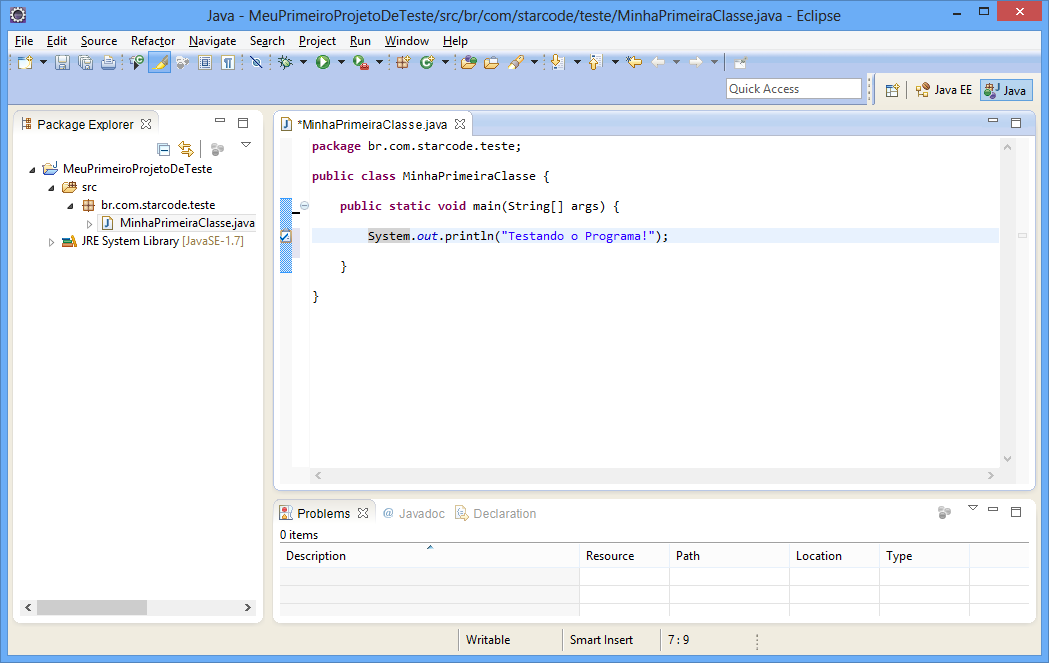
Vamos editar o método main da nossa classe. Este método é especial para o Java, pois a execução do programa incia-se nele. Primeiro remova a linha com o comentário TODO, depois digite o conteúdo abaixo no lugar:
System.out.println("Testando o Programa!");
Teremos o conteúdo da imagem abaixo.
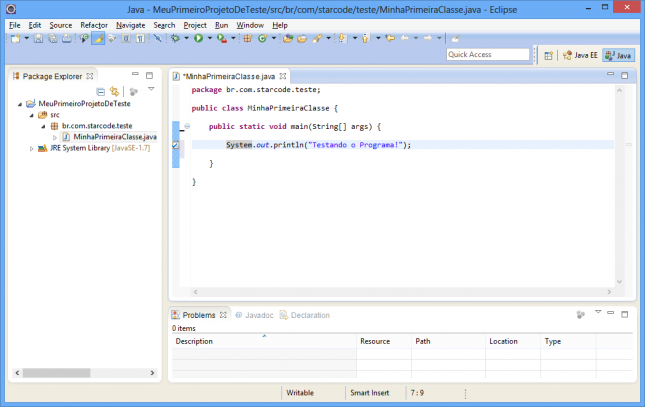
Não se esqueça de salvar o arquivo. Pressione Ctrl+S ou clique em File > Save.
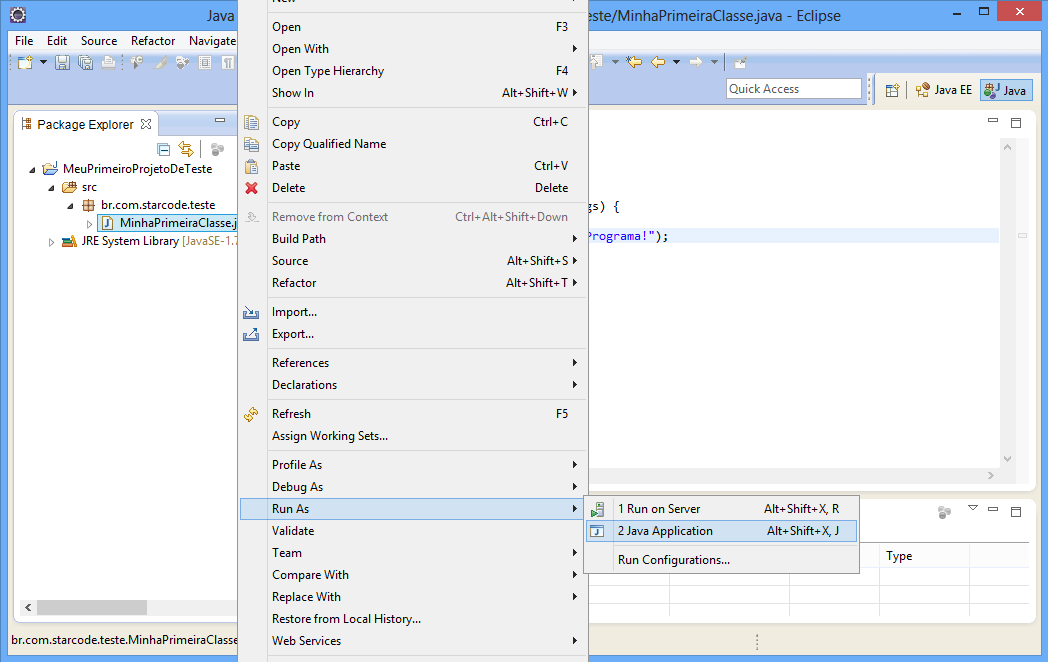
E finalmente vamos executar nosso primeiro programa em Java. Clique com o botão direito do mouse sobre a classe e acesse o menu Run As > Java Application.
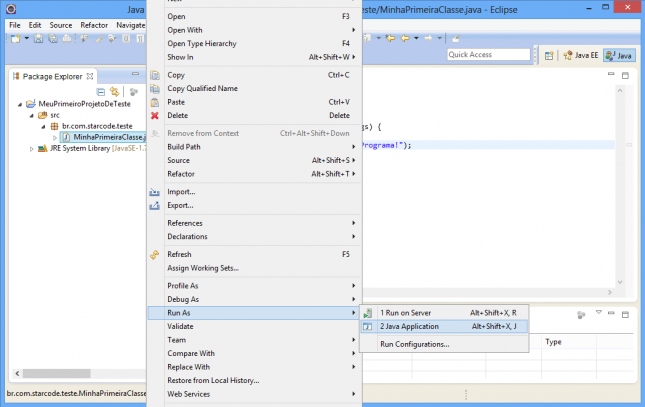
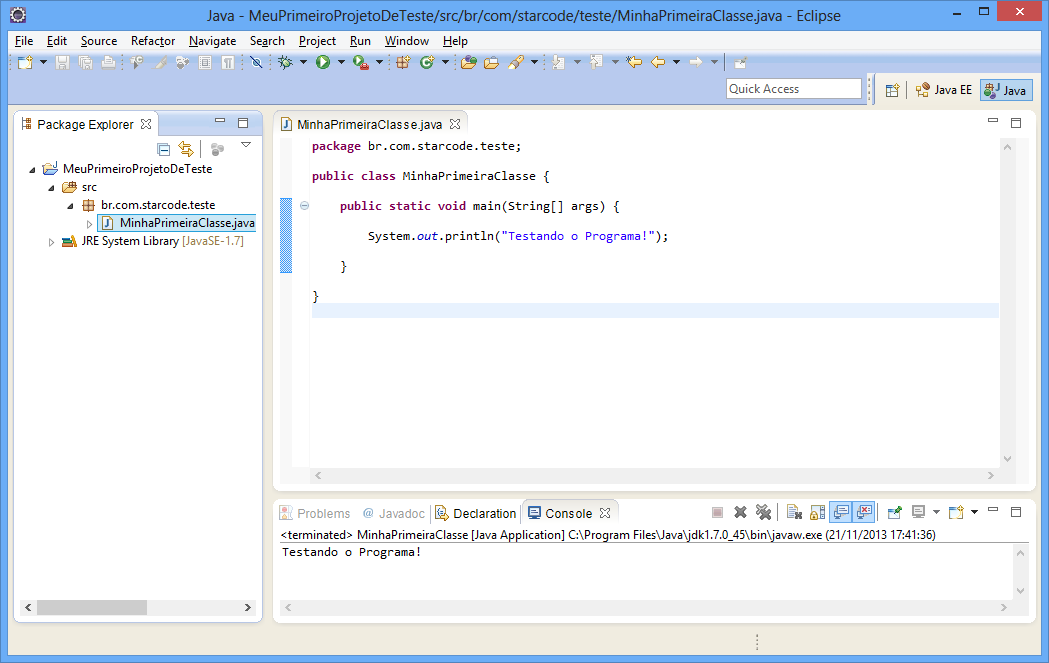
A view Console será aberta, exibindo a saída que nosso programa imprimiu e provando o sucesso da execução.
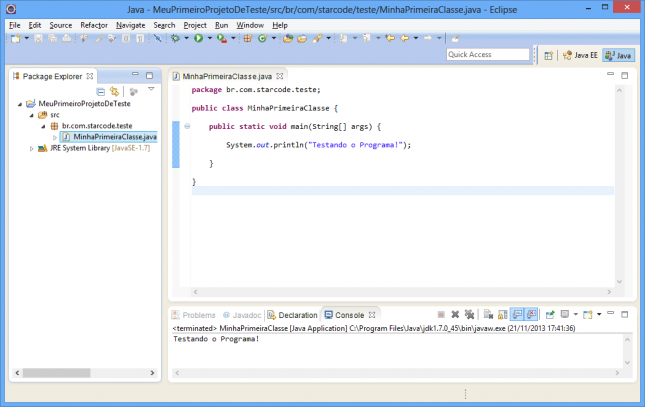
Depurando o programa
Aproveitando o exemplo da execução, vamos supor que você precisa fazer a depuração (debug) do programa por algum motivo. A depuração permite interromper temporariamente a execução do programa em um determinado ponto, inspecionar e alterar valores de variáveis e continuar a execução linha a linha para analisar o comportamento do programa.
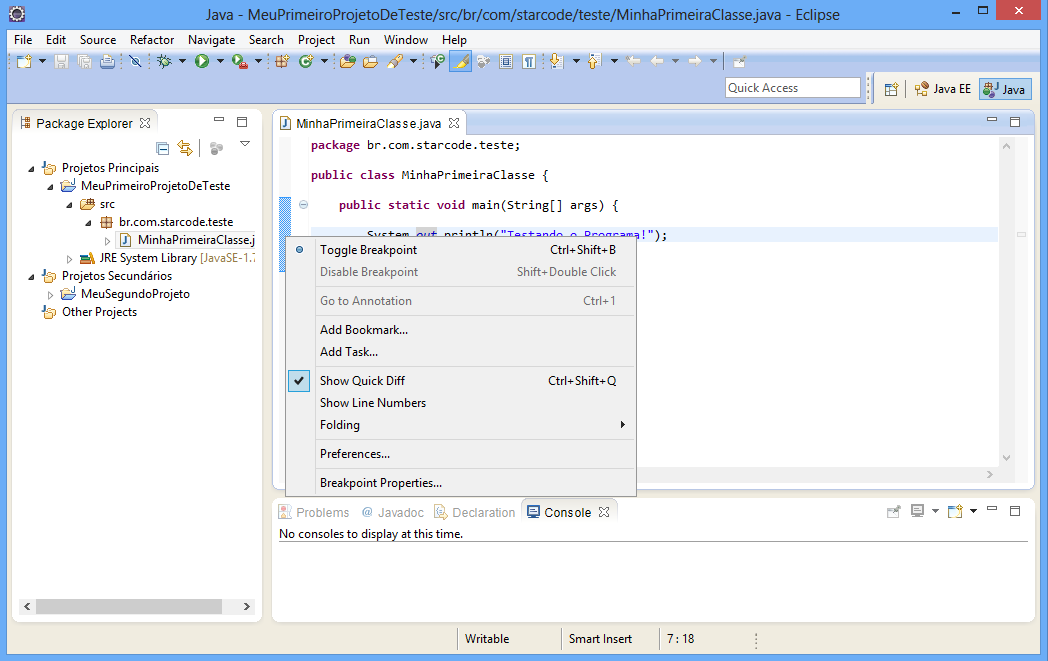
Antes de iniciar a depuração, vamos criar um breakpoint, isto é, vamos marcar a linha onde queremos que a execução do programa seja interrompida. Existem várias formas de fazer isso, por exemplo:
- Clique na linha desejada e pressione
Ctrl+Shift+B.
- Dê um duplo clique na barra azul à esquerda do editor, na altura da linha desejada.
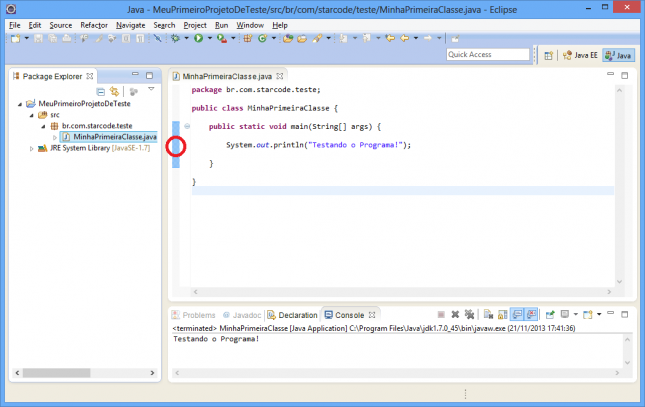
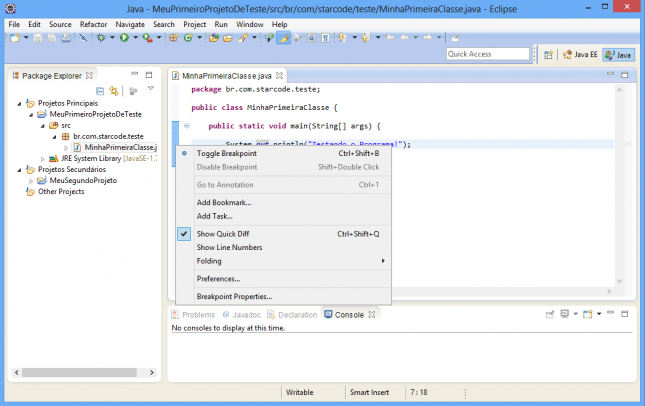
- Clique com o botão direito na barra azul à esquerda do editor e selecione a opção Toggle Breakpoint.
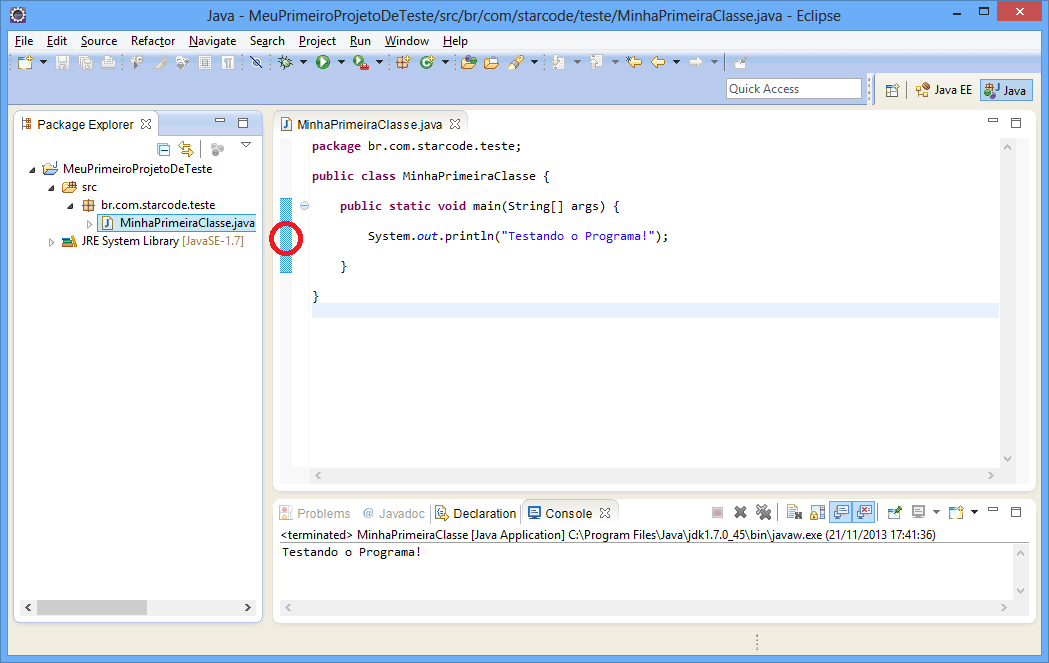
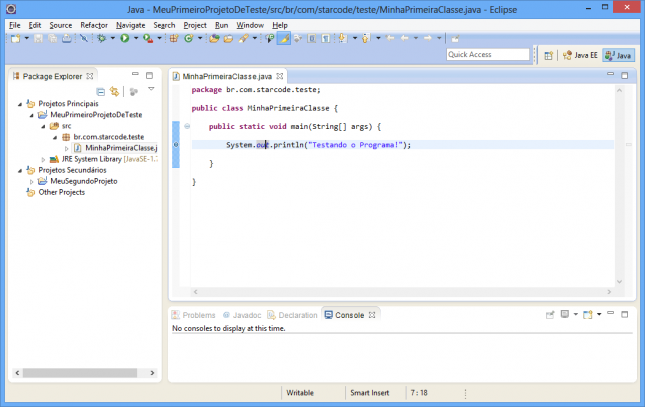
O resultado é uma bolinha azul à esquerda da linha, conforme a imagem abaixo.
Para remover o breakpoint, execute novamente um dos procedimentos citados (tecla de talho, duplo clique ou menu de texto).
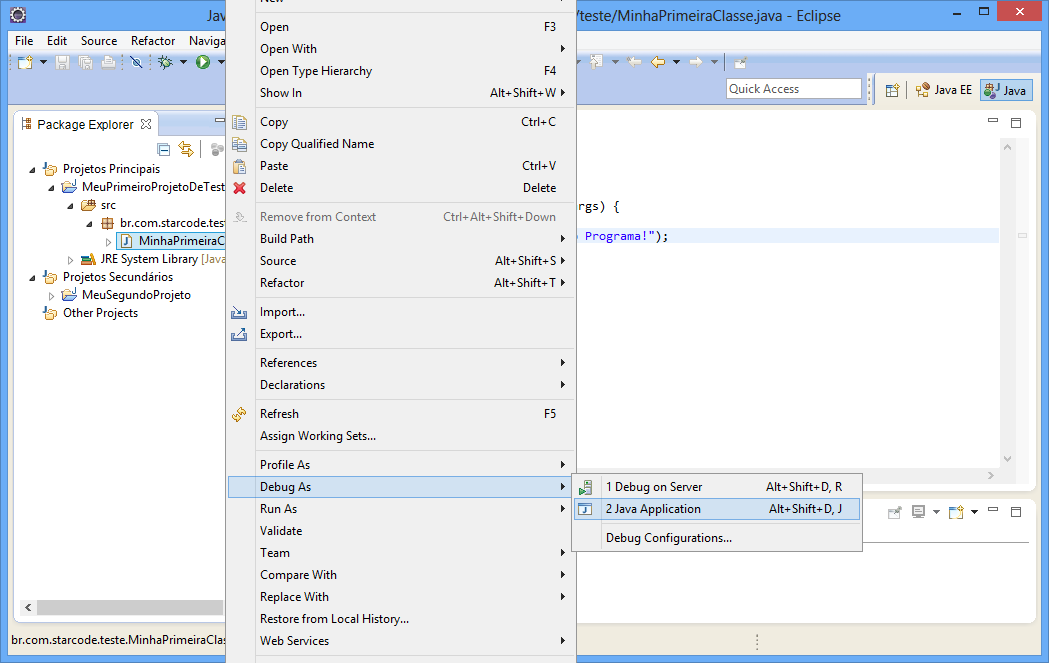
Agora vamos executar o programa em modo de depuração (debug mode). Clique com o botão direito sobre a classe e acesso o menu Debug As > Java Application.
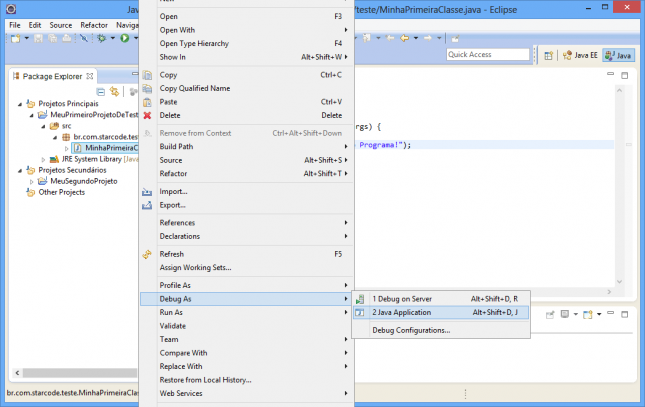
Após o início da execução, quando um breakpoint for encontrado, o Eclipse irá perguntar se você deseja mudar a visualização para a perspectiva Debug.
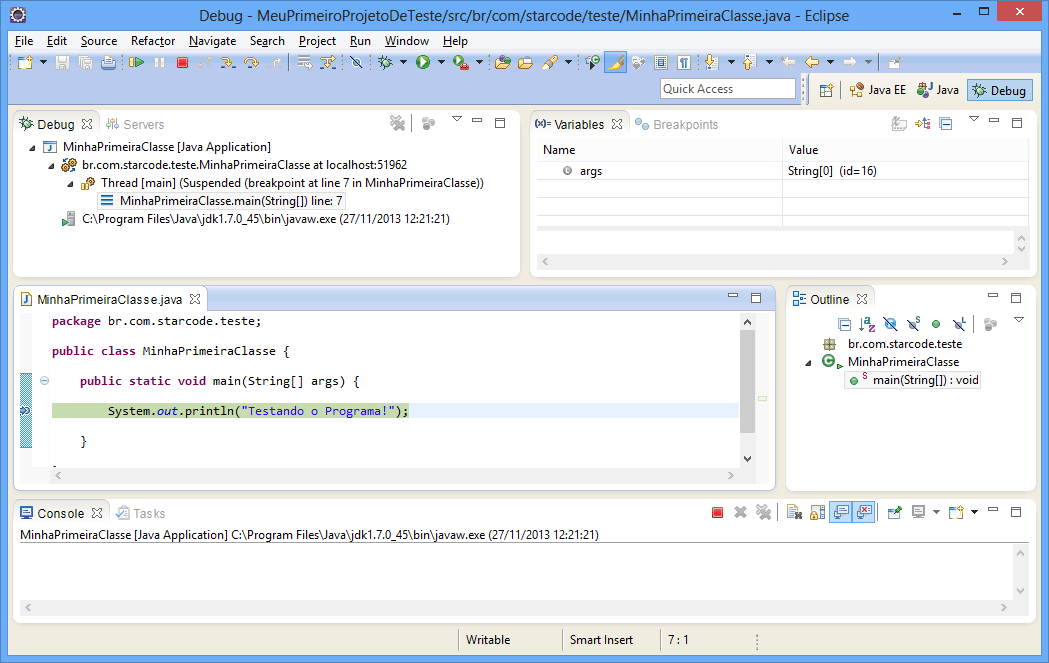
Clique em Yes e a tela do Eclipse mudara, exibindo outras views e a linha atual sendo executada em verde claro no editor.
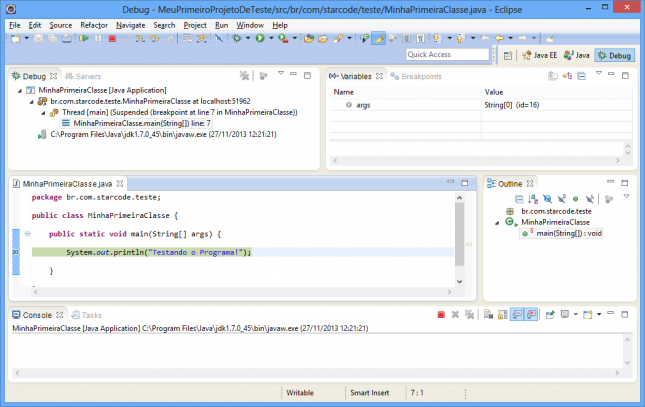
Confira alguns detalhes da tela acima:
- Debug: view que exibe as threads do programa atual e a pilha de chamadas. Como temos apenas um programa simples, há apenas uma thread. E como estamos na classe principal, o único item da pilha consiste do nome da classe, do nome do método e do número da linha sendo executada.
- Variables: view que exibe as variáveis do escopo atual, de forma que você pode ver e até modificar os valores.
- Breakpoints: view que exibe todos os breakpoints do workspace.
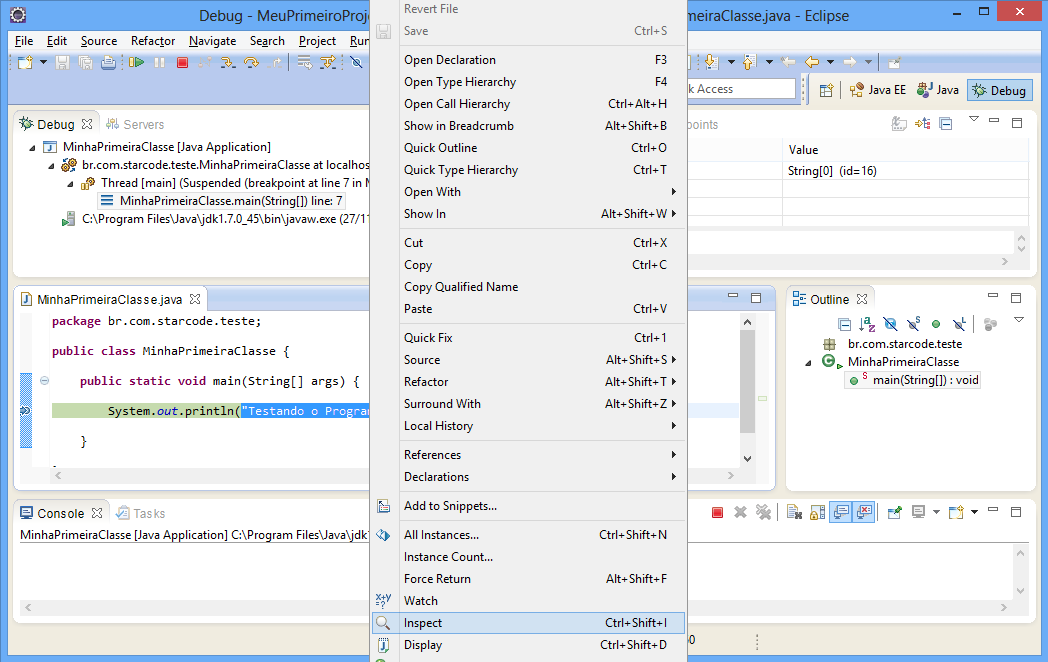
Neste momento, estamos com a execução do programa interrompida na linha 7. Além de conferir as variáveis do escopo atual, você pode executar um trecho do código e conferir o valor retornado através do Inspect.
Como não temos nenhuma variável, vamos inspecionar o texto contido na função println. Selecione o texto, clique com o botão direito e selecione o menu Inspect.
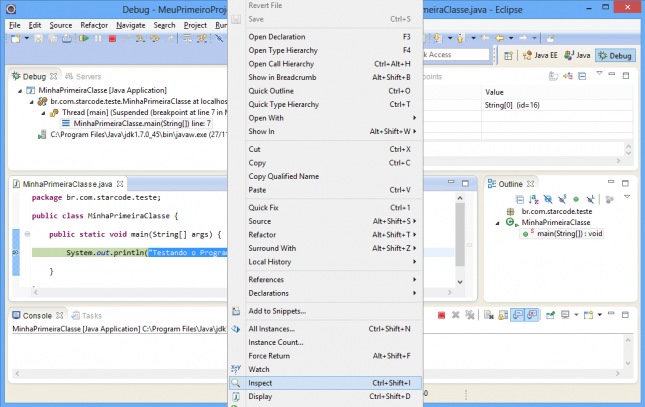
O Java irá executar o trecho selecionado e retornar o resultado numa caixa amarela, conforme a imagem abaixo:
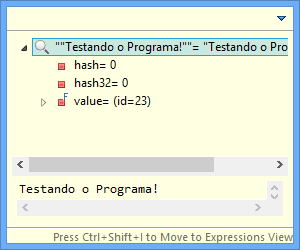
Embora em nosso exemplo tenhamos usado uma String simples, poderíamos ter feito com qualquer trecho, por exemplo, uma conta matemática ou uma chamada de método. Apenas tome um certo cuidado com a função Inspect, pois o código selecionado é realmente executado, afetando variáveis e valores do seu programa.
Dicas para organização e manutenção de projetos
Logo seu Workspace pode ficar abarrotado de projetos e, consequentemente, o desempenho do Eclipse e sua experiência como desenvolvedor cairão drasticamente. Além de separar seus projetos em vários Workspaces, existem técnicas que ajudam no dia-a-dia, tanto no que se refere à organização quanto ao desempenho.
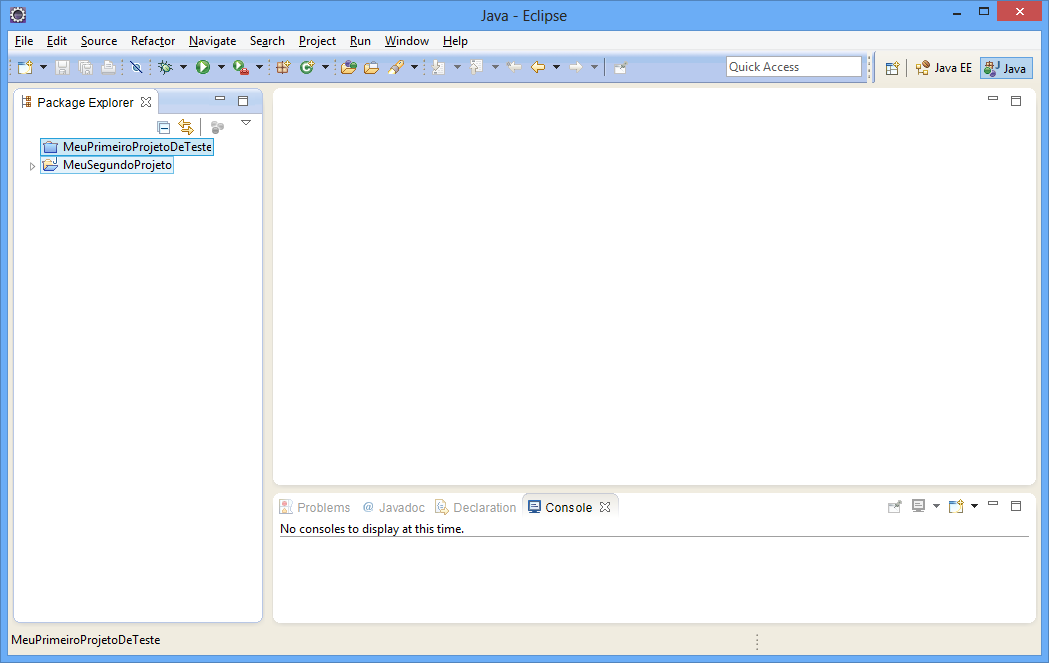
Vamos criar um projeto adicional para efeito de exemplo. Siga os passos anteriores, mas crie um projeto com outro nome.
Veja como ficou o Workspace:
Seguindo nosso exemplo, vamos supor que não queremos mais usar o primeiro projeto por algum tempo. Nós podemos fechá-lo, de modo que ele ainda existirá, mas não ocupará recursos. Ao fechar um projeto, o Eclipse não listará os arquivos nem fará cache das classes contidas nele. Para fechar um projeto, clique com o botão direito sobre ele e selecione a opção Close Project.
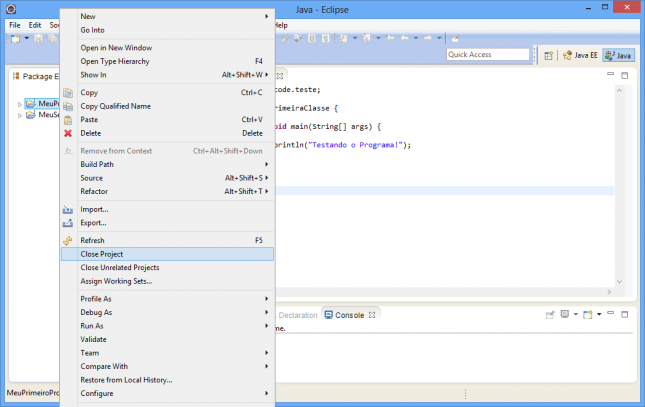
O ícone do projeto vai mudar e você não poderá mais acessar o seu conteúdo até abri-lo novamente.
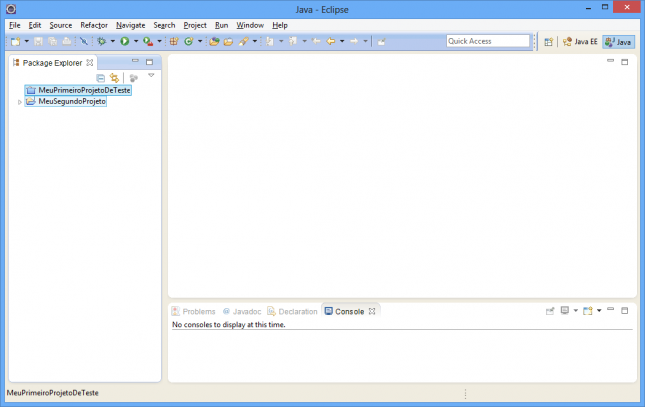
Se desejar abrir o projeto para acessar os arquivos, dê um duplo clique no mesmo ou clique com o botão direito e selecione o menu Open Project. Não precisa fazer isso agora.
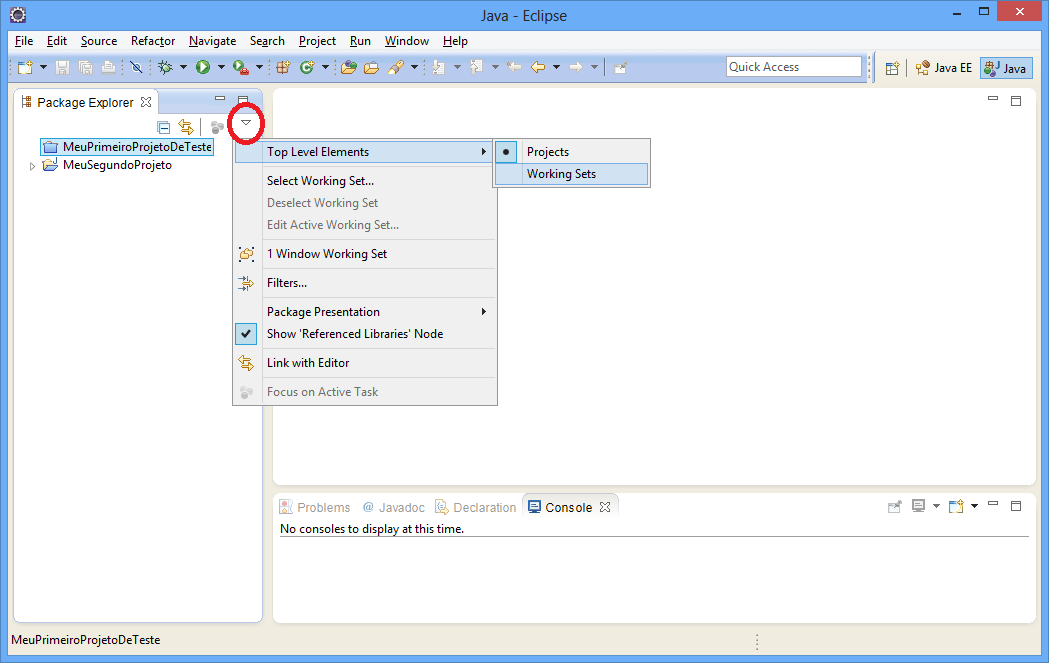
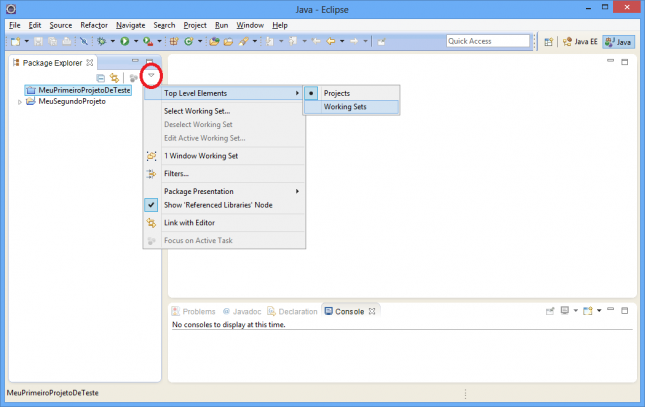
Partindo para outro exemplo, vamos supor que você está com muitos projetos no Workspace. Há alguma forma de agrupá-los e organizá-los adequadamente? Para isso existem os Working Sets.
Vamos criar dois Working Sets. Clique no menu da view Package Explorer (conforme indicado em vermelho na imagem abaixo) e então selecione a opção Top Level Elements > Working Sets.
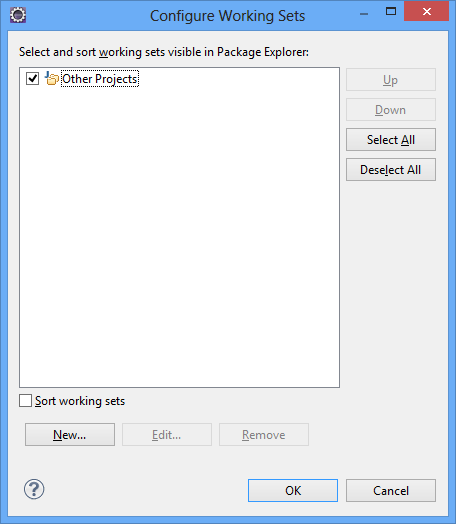
A tela de configuração dos Working Sets é exibida:
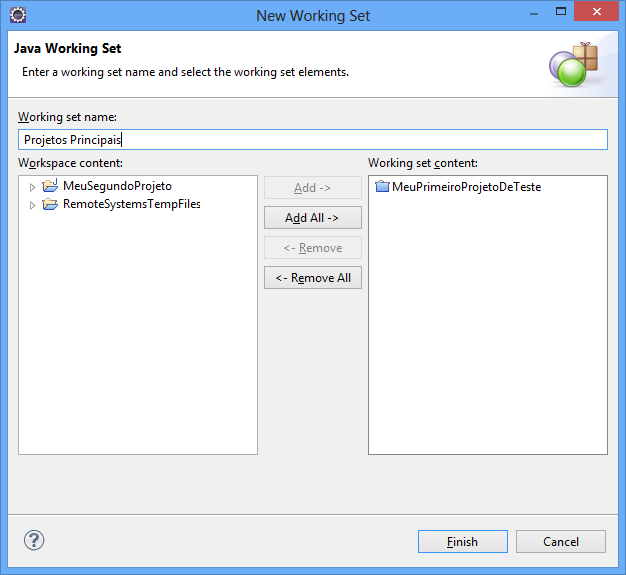
Primeiramente vamos criar um Working Set chamado “Projetos Principais” com o nosso primeiro projeto. Clique no botão New..., digite o Working set name, adicione o projeto na lista da direita (Working set content) e clique em Finish.
Depois, clique novamente em New... e repita a operação para criar outro Working Set chamado “Projetos Secundários”, incluindo desta vez o segundo projeto que criamos.
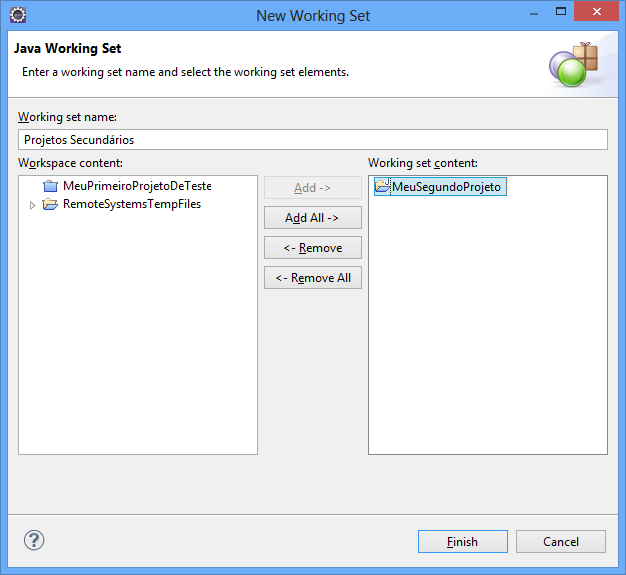
Após confirmar a inclusão você pode ordenar os Working Sets. Selecione um item da lista e clique em Up para mover o item para cima ou em Down para mover o item para baixo. A ordenação final ficou da seguinte forma:
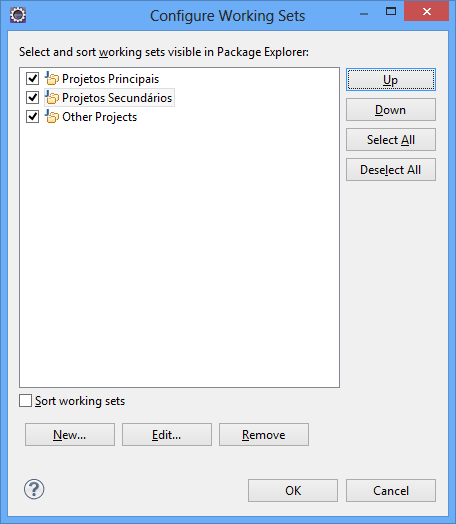
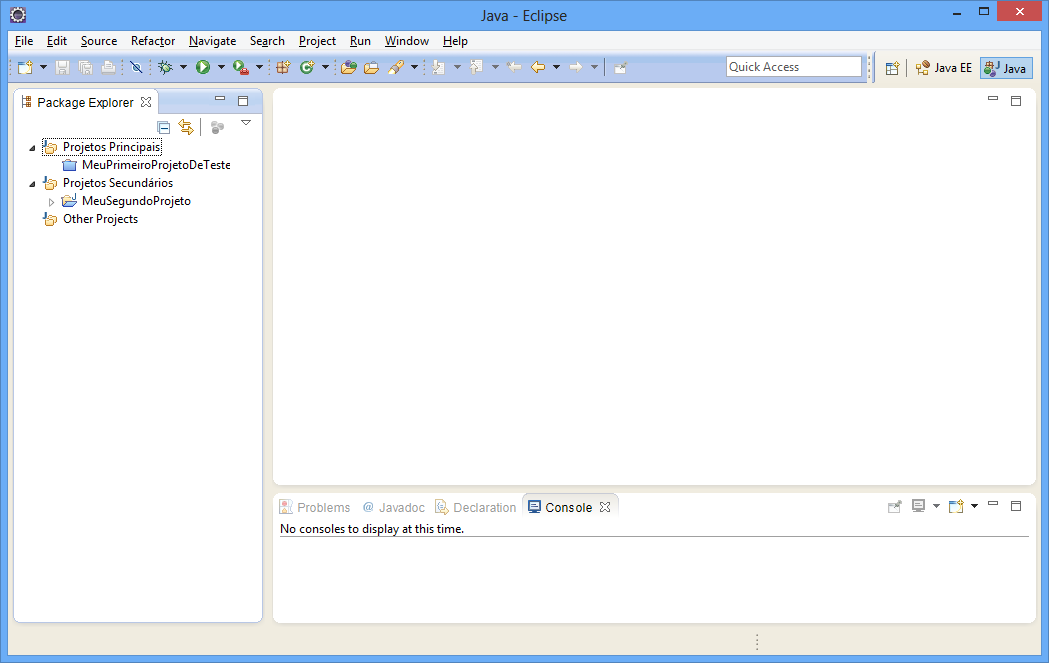
Clique em OK e confira o resultado:
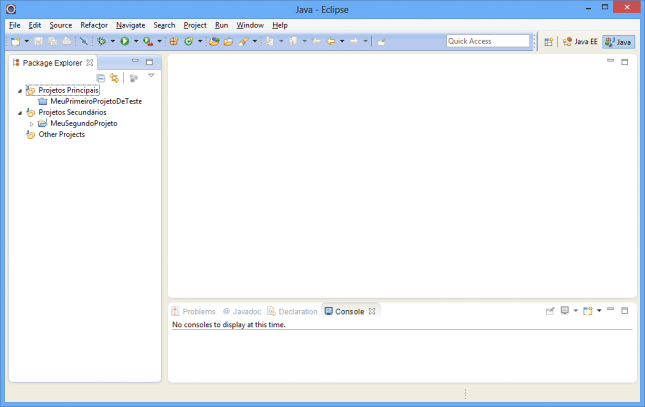
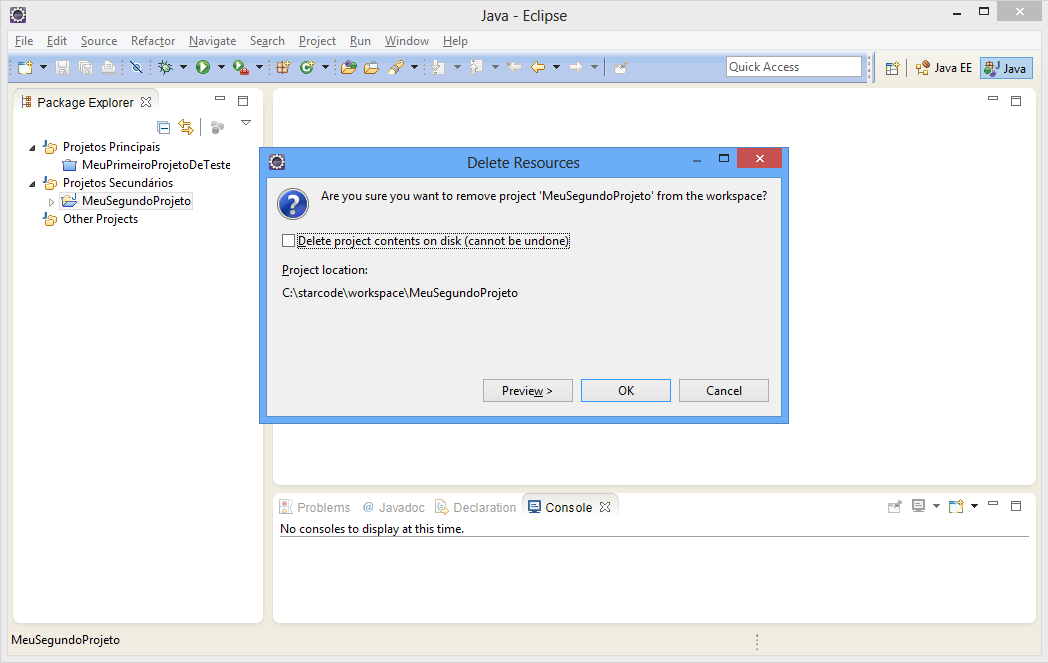
Por fim, se quiser excluir um projeto do seu Workspace, selecione o item e pressione a tecla Delete. Uma tela de confirmação será exibida.
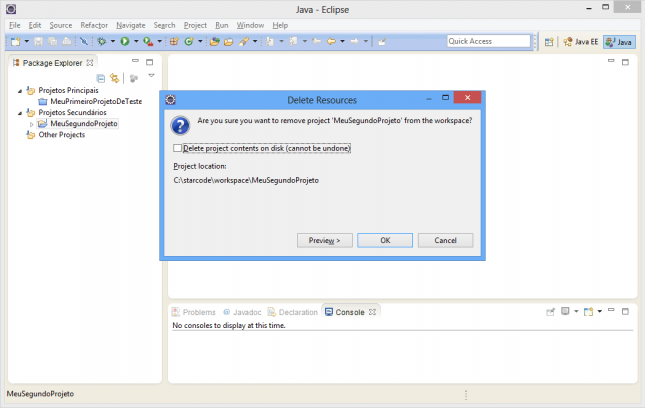
Note que existe uma opção chamada “Delete project contents on disk (cannot be undone)”. Caso a opção não esteja marcada o projeto será excluído do Workspace, mas não do seu disco rígido. Isso é importante caso não queira perder os dados ou esteja usando o projeto em outro Workspace. Caso a opção esteja marcada, o projeto e todos os arquivos contidos nele serão removidos não apenas do Eclipse, mas também apagados do seu disco, não sendo possível recuperá-los.
Resumo
Neste tutorial você aprendeu a baixar, instalar, configurar o Eclipse. Também viu como criar e organizar projetos, além de executar e depurar um programa simples em Java.
Apesar de tratar-se de uma introdução básica, este tutorial lhe dá uma base para avançar para usos mais avançados da plataforma Java, os quais disponibilizarei em breve.