
Bancos de dados relacionais que operam no padrão SQL em geral são transacionais, isto é, eles permitem a execução de uma sequência de operações como um bloco indivisível de forma a garantir a integridade dos dados em um ambiente com acesso concorrente.
O Problema
Imagine três operações sequenciais que afetam a base de dados e não usamos uma transação para controlá-las. Vamos usar como exemplo um caso de uso comum de um e-commerce:
- Verificar se possui o produto em estoque
- Inserir um novo registro da compra
- Debitar o estoque
Agora vamos supor que dois clientes estão tentando finalizar suas compras neste e-commerce fictício. O servidor recebe duas requisições quase simultaneamente e começa a processar os pedidos na sequência apresentada acima. Os dois pedidos estão sendo processados paralelamente em threads diferentes. Tanto o cliente A quanto o cliente B selecionaram um produto com apenas uma unidade em estoque.
Podemos acabar com a seguinte linha de execução:
- Thread A verifica o estoque (passo #1) e insere o registro da compra (passo #2)
- thread A é bloqueada e B passa a ser executada
- Thread B verifica o estoque (passo #1), o qual ainda não foi debitado, e insere o registro da compra (passo #2)
- Thread B atualiza o estoque (passo #3), que agora fica zerado
- Thread B é bloqueada e A passa a ser executada
- Thread A atualiza o estoque (passo #3), que agora fica negativo!
Apesar de verificarmos o estoque a ordem de execução dos diferentes processos é imprevisível, então neste cenário concorrente ela não traz garantia do valor no passo seguinte.
A Solução
Bancos de dados transacionais usam o conceito ACID:
- Atomicidade: uma transação é uma sequência de operações indivisível, ou é executado como um todo, ou tudo é desfeito.
- Consistência: ao final da transação, o estado dos dados deve ser consistente.
- Isolamento: embora alguns sistemas permitam quebrar o isolamento, em geral, uma transação em andamento não pode ser acessada por outras transações de modo a evitar leitura de um estado inconsistente, uma “sujeira”.
- Durabilidade: em caso de sucesso (commit) a persistência dos dados deve ser garantida
Para garantir esses conceitos, em geral, os bancos de dados usam bloqueios quando ocorrem acessos simultâneos à mesma estrutura de dados. Ou seja, se alguém já está mexendo nos dados, os demais tem que aguardar sua vez numa fila até ele acabar.
Na prática
Ao usar bancos de dados transacionais, nós podemos usufruir deste controle de gerenciamento por parte dos SGBDRs (Sistemas Gerenciadores de Bancos de Dados Relacionais).
Incluindo o conceito de transação ACID no exemplo anterior, vamos ver como fica a execução:
- Thread A inicia uma transação, verifica o estoque (passo #1) e insere o registro da compra (passo #2)
- Thread A é bloqueada e B passa a ser executada
- Thread B inicia uma transação, mas ao tentar verificar o estoque ela é bloqueada porque a transação de A ainda não acabou
- Thread A atualiza o estoque, que agora fica zerado, e faz commit na transação.
- Thread B é desbloqueada e passa a ser executada
- Thread B conclui a verificação do estoque (passo #1) e retorna um erro pois não encontra o produto disponível no estoque
- Thread B executa um rollback para desfazer outras alterações que tenha efetuado, por exemplo, se houve outro produto debitado na mesma transação.
O resultado final é como se somente a thread A tivesse executado e B nunca existisse.
Nem tudo é um mar de rosas
Existem alguns problemas inerentes a transações ACID, sendo o desempenho o maior deles.
Embora seja importante garantir a integridade dos dados, para muitos sistemas onde a disponibilidade é o fator mais crítico um modelo que bloqueia acessos simultâneos torna-se inviável. Este é um dos principais fatores para o surgimento e a adoção de diversos sistemas de bancos de dados não transacionais e NoSQL.
O importante é entender que o uso de transações tem um custo e em algumas ocasiões este pode ser alto demais. Uma das representações mais comuns do trade-off de persistência de dados é a seguinte (retirada deste artigo):
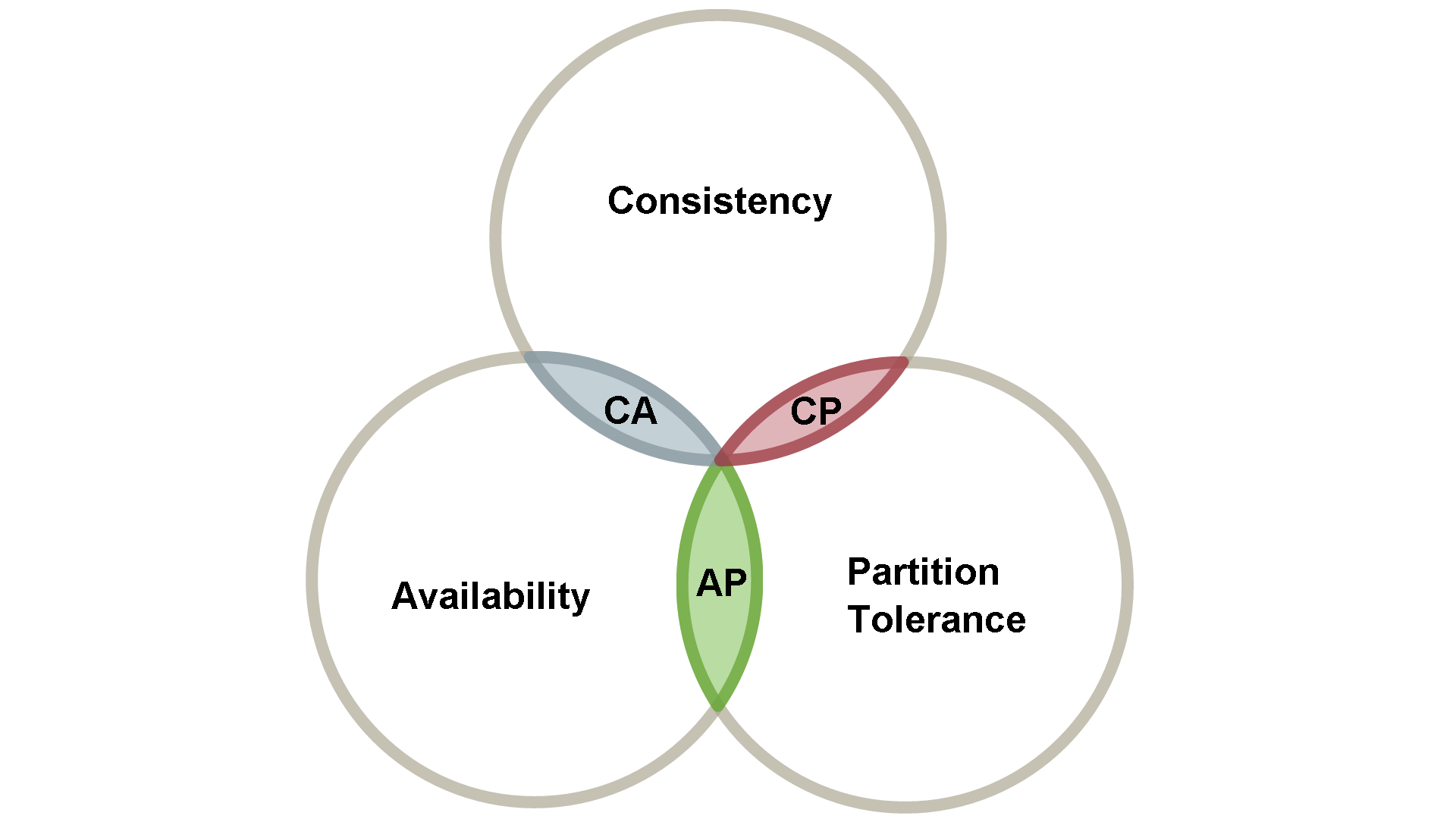
O gráfico demonstra que consistência, disponibilidade e particionamento (escalar o banco de dados em diversos nós) são recursos que afetam uns aos outros. Você simplesmente não pode ter o melhor dos três e isso foi provado no teorema de CAP.
Bancos de dados relacionais geralmente sacrificam o particionamento em prol da consistência e da disponibilidade, enquanto alguns sistemas NoSQL sacrificam a consistência dos dados.
Note que o termo “geralmente” ou “em geral” foi cuidadosamente utilizado no artigo porque os diferentes sistemas de bancos de dados permitem vários níveis de configuração de isolamento de transações e acesso simultâneo, possibilitando um ajuste fino do desempenho de cada funcionalidade
Este artigo foi baseado na minha resposta no StackOverflow em Português!

