Talvez você já tenha ouvido falar que em Java não é preciso preocupar-se com gerenciamento de memória, ou ainda que em Java a memória nunca acaba por causa do Garbage Collector (GC).
Bem, estou aqui para lhe dizer que tudo isso é besteira. Depois de erros banais como NullPointerException e SqlException, os problemas mais sérios e comuns que tenho visto ao longo dos anos são justamente relacionados à memória, isto é: OutOfMemoryError.
Seja por falta de configuração adequada ou implementação equivocada. Código ruim pode alocar objetos indeterminadamente sem remover as referências a eles, de forma que nem o GC dá um jeito. Porém, neste artigo vamos focar na parte de configuração.
O erro OutOfMemoryError manifesta-se em duas formas principais: Java Heap Space e PermGen Space. Ambos são, respectivamente, relacionados a trechos de memória dinâmico e permanente do Java.
A maioria das aplicações sérias passa, em algum momento, por ajustes na quantidade de memória disponível tanto para a seção dinâmica quanto para a seção permanente.
Vamos ver o que é tudo isso e como efetuar a configuração.
Heap Space (Memória dinâmica)
O Heap Space é o local onde o Java armazena suas variáveis e instâncias de objetos. Este espaço de memória pode aumentar ou diminuir ao longo do tempo, dinamicamente, de acordo com a quantidade de objetos usados no programa.
Para definir quanta memória pode ser usada pelo Java, é preciso informar parâmetros ao executar a JVM. Caso você não saiba, executar o java cria uma nova instância da JVM, portanto qualquer parâmetro passado a este programa é uma configuração para essa JVM.
Já dei uma breve introdução sobre isso no artigo Instalando, Configurando e Usando o Eclipse Kepler, porém cada programa pode ter seu modo de configurar. Se você está usando um programa qualquer ou um servidor de aplicação (JBoss, Websphere, Weblogic, Glassfish, Tomcat, etc.), procure na documentação do mesmo onde fica a configuração dos parâmetros de memória.
Neste artigo, vou exemplificar uma chamada diretamente ao comando java via linha de comando.
Quantidade máxima de memória dinâmica
O parâmetro Xmx define a quantidade máxima de memória dinâmica que a Máquina Virtual Java pode alocar para armazenar esses objetos e variáveis.
É importante definir uma quantidade máxima de memória razoavelmente maior do que a média usada na aplicação para evitar não só OutOfMemoryError como também escassez de memória.
Trabalhar no limite da memória disponível faz o Garbage Collector executar muitas vezes para coletar objetos não usados e isso resulta em pausas indesejadas no programa durante a varredura dos objetos.
Quantidade inicial de memória dinâmica
O Xms define a quantidade inicial de memória dinâmica alocada no início da JVM.
É importante verificar quanto sua aplicação usa em média e definir um valor próximo disso. Dessa forma, não ocorrerão muitas pausas para alocação de memória, resultando em um desempenho maior de inicialização até o ponto em que a aplicação está executando num patamar estável.
PermGen Space (Memória permanente)
O Java também possui a PermGen Space, outra parte da memória chamada de “estática” ou “permanente”, utilizada para carregar suas classes (arquivos .class), internalizar Strings (string pool), entre outras coisas.
Como regra geral, a memória permanente não pode ser desalocada. Isso implica que, por exemplo, se sua aplicação tem muitos Jars e carrega muita classes, em algum momento poderá ocorrer um erro de PermGen Space. Isso é comum com quem abusa de frameworks com modelos de classes “pesados”, sendo um cenário comum a turminha JSF, PrimeFaces, Hibernate e JasperReports.
O erro ocorre porque não é possível ao Java carregar novas classes quando não há espaço e não é mais possível aumentar a memória permanente, pois não dá para descartar classes já carregadas para dar lugar a novas.
Da mesma forma que na memória Heap, é possível informar à JVM a quantidade de memória permanente máxima que pode ser alocada e a quantidade de memória permanente inicialmente alocada.
O parâmetro XX:MaxPermSize define a quantidade máxima de memória permanente que a JVM pode utilizar e o parâmetro XX:PermSize define o tamanho inicial alocado.
Os mesmos princípios mencionados anteriormente para definição de quanta memória Heap deve ser reservada podem ser aplicados aqui.
Gerações de Objetos
A seção dinâmica da memória, Heap Space, é ainda dividida entre “nova” e “velha” geração.
A seção da “nova geração” (Young Generation) é reservada para a criação de objetos. É o berçário do Java. Estatisticamente, os objetos recém-criados são mais suscetíveis a serem coletados.
Após ter algum tempo de vida, o GC pode promover os objetos que não forem coletados para a seção da “velha geração” (Old Generation), onde ficam os objetos com mais tempo de vida e com menos chances de serem coletados.
Os parâmetros XX:MaxNewSize e XX:NewSize definem, respectivamente, a quantidade máxima de memória reservada para os objetos da “nova geração” e a quantidade inicial de memória para tais objetos.
Note que a memória da “nova geração” fica dentro do espaço do Heap Space, portanto cuidado com os valores definidos.
Nunca tive a necessidade de modificar esses parâmetros e creio que na grande maioria dos casos você também não vai precisar. Use-os somente em caso de última necessidade.
Ilustração da divisão de memória da JVM
A imagem a seguir ilustra os conceitos apresentados no artigo:
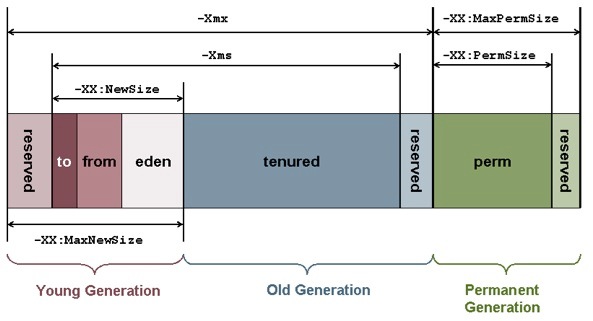
A memória total alocada pelo Java é a soma do Heap Space e PermGen Space. O espaço para a Young Generation fica dentro do Heap.
Exemplo
Cada programa Java tem sua forma de configuração, porém ao executar diretamente o comando java, você pode simplesmente passar os parâmetros da seguinte forma:
java -Xmx2g -Xms1024m -XX:MaxPermSize=1g -XX:PermSize=512m
No exemplo acima, definimos:
-Xmx2g: Quantidade máxima de memória dinâmica de 2 Gigabytes-Xms1024m: Quantidade inicial de memória dinâmica de 1024 Megabytes ou 1 Gigabyte-XX:MaxPermSize=1g: Quantidade máxima de memória permanente de 1 Gigabyte-XX:PermSize=512m: Quantidade inicial de memória permanente de 512 Megabytes
Considerações
As configuração de memória apresentadas neste artigo resolvem 90% ou mais dos problemas cotidianos relacionados à memória com a JVM. Entretanto, este é apenas o tipo de ajuste mais básico que existe.
Você pode encontrar informações bem mais detalhadas, incluindo parâmetros de configurações específicas, em artigos voltados para otimização da JVM. Por exemplo:
Por fim, é importante lembrar que não existe uma fórmula mágica para determinar valores de memória para um sistema. Antes, deve ser levado em conta o tipo de uso, recursos utilizados, quantidade de usuários e capacidade do hardware.
Não creio que isso possa ser determinado objetivamente por alguma fórmula, mas através de um processo dedutivo conduzido por um profissional experiente.
Este artigo foi baseado em minha resposta no Stack Overflow em Português.