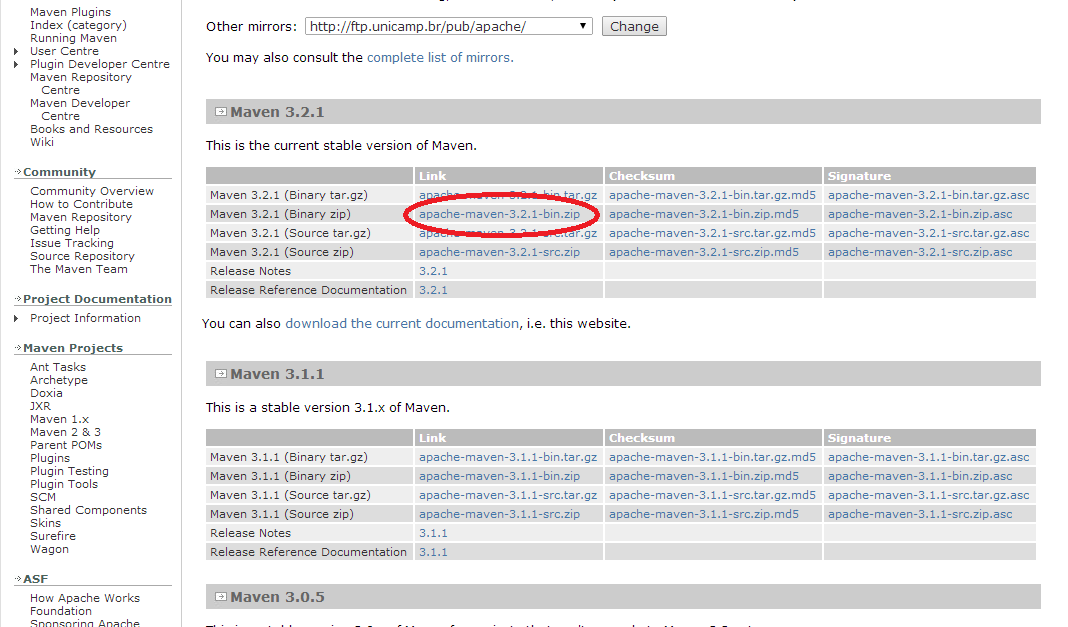
Programador, Analista, Desenvolvedor, Engenheiro de Software. Não importa qual o título adotado. Você escreve código? Então é mais um que caiu nessa “cilada”! 😉
Brincadeiras à parte, a área de desenvolvimento de software é uma das mais comentadas, desejadas, amadas e até odiadas da atualidade. Sendo sua história relativamente recente, ainda há muita confusão sobre a identidade do profissional de TI.
Isso se reflete na dificuldade de muitos, senão todos, profissionais ao tomar decisões sobre carreira. O que devem estudar? Vale a pena saber a linguagem X? Em que se especializar?
Todos já ouviram o mantra de que em TI “é necessário estar sempre se atualizando”. Esta é mais uma frase pronta que, de tantas vezes repetida, já perdeu completamente o significado e o impacto em nossas mentes.
Quero agora levá-lo a uma breve reflexão sobre o seu desenvolvimento como profissional e tentar responder de forma geral às indagações acima.
Sim, TI é complicada
Brooks escreveu na edição especial do livro The Mythical Man-Month, lançada em 1995, que ele já não conseguia mais acompanhar o avanço em todas as áreas da Engenharia de Software como antigamente. Quem dirá hoje!
A situação piorou muito. A cada ano aumenta a gama de conhecimento, plataformas, linguagens, frameworks e ferramentas. Os formandos que vão trabalhar com software precisam sair da faculdade dominando conceitos que foram formulados ao longo de anos, décadas e até séculos. É como se cada turma saísse da faculdade sabendo menos que a anterior, já que existem sempre novidades e o gap de informação aumenta.
Essa gigantesca gama de informações faz com que muitos fiquem ansiosos sobre a infinidade de tecnologias a serem aprendidas. E as empresas parecem procurar super programadores que parecem já ter nascido sabendo tudo.
Algumas vezes já fiquei bastante ansioso por conhecer tão pouco e ver cada dia novas tecnologias sendo lançadas. Parecia nunca ter fim!
Não se desespere
Apesar do cenário acima, precisamos compreender que leva tempo para se aprender bem qualquer profissão. Alguns dizem que leva uma média de 10 anos para alguém ser realmente bom no que faz. E pesquisas indicam que passamos a gostar mais do que fazemos proporcionalmente ao tempo que nos dedicamos aquela atividade.
Além disso, não se deixe levar por aquelas milhares de siglas que você não entende, por exemplo quando você olha aquelas vagas de emprego que pedem centenas de conhecimentos que você nem tem ideia do que são. Isto é algo possível de se conhecer com o tempo.
Não estou dizendo que é fácil. É preciso se esforçar bastante, mas o segredo é ter calma, paciência e persistência. Então você poderá planejar seu avanço profissional dentro de suas capacidades e estudar rotineiramente sem desistir ou desanimar.
Ninguém nasce sabendo
Você não precisa saber de tudo para atuar numa certa área. Aliás, faculdade ou curso algum vai ensinar o que é realmente preciso para encarar um trabalho desafiador ou mesmo empreender em seu próprio negócio.
Basta aprender o necessário para cada fase de sua carreira. Para quem está começando em TI, o importante é conhecer bem os fundamentos da computação, orientação a objetos e pelo menos uma linguagem de programação. Depois disso, é importante intercalar ciclos de estudo e trabalho prático para começar o amadurecimento profissional.
Em minha experiência é importante pensar iterativamente, isto é, em ciclos. Você pode traçar uma meta de aprender profundamente sobre uma tecnologia por ano ou a cada 6 meses, dependendo do seu ritmo. Aí você pode gastar o primeiro mês estudando livros e apostilas, o segundo implementando um protótipo simples, o terceiro estudando um pouco mais a fundo, o quarto tentando criar um projeto mais sério, o quinto lendo material mais difícil sobre o assunto e assim por diante.
Especialistas
Persistindo nos estudos, muitos profissionais acabam se especializando num subconjunto de conhecimentos de uma das áreas de TI. Tornam-se especialistas.
Isso fica bem visível ao analisar alguns eventos de TI. É possível observar diferentes nichos de tecnologias, com palestras e cursos voltados para cada subcultura de TI, cada uma com um público bem específico.
É bom especializar-se em algo. Trabalhar e estudar diferentes aspectos de alguma tecnologia por alguns anos é um grande investimento, pois você passa a ser distinto dentro desse segmento.
Porém, a especialização tem lados positivo e negativo.
Especialistas e especialistas
Como mencionei, há algumas pessoas que são especializadas porque se aplicaram consideravelmente em conhecer determinado assunto.
Por outro lados, outras são “especialistas” porque não se aplicaram em conhecer nada além daquilo que já usam no dia-a-dia.
Enquanto os especialistas de verdade estão dentro da média na maioria dos assuntos e dominam sua especialidade, há os falsos especialistas que não se interessam por nada que não é necessário para eles.
Respeitando a individualidade
Devo fazer uma consideração aqui. Precisamos entender que nem todas as pessoas que trabalham em TI são aficionadas por programação ou questões técnicas.
Conheço bons profissionais, organizados e produtivos, mas que não chegam perto de serem bons programadores. Nem todos os “especialistas” e bons profissionais são necessariamente bons programadores. A Engenharia de Software possui muitas disciplinas que envolvem outras áreas.
Não devemos cair no grande erro de muitos educadores no decorrer da história, o qual tem impactado nossa geração inteira. Estou falando da padronização do que é considerado “inteligência” ignorando as singularidades de cada indivíduo. Isso nada mais é do que dar vantagem a um perfil específico em detrimento dos demais.
Muitas empresas e muitos profissionais ignoram isso e inconscientemente geram incalculáveis prejuízos para si mesmas. Aliás, os profissionais que coordenam processos seletivos deveriam ser os melhores da empresa, porque nada como um excelente profissional para identificar as potencialidades dos entrevistados. Porém, o que geralmente ocorre é que essa tarefa fica relegada a profissionais, no mínimo, medíocres. E o resultado são contratações, no mínimo, medíocres.
Enfim, se você não é um programador, ainda pode aplicar todas as dicas que tentou passar aqui em sua área de conhecimento.
Generalistas
Outro perfil profissional é do generalista, isto é, aquele que estuda diferentes áreas, não ficando muito tempo em apenas uma coisa.
Por muito tempo ouvi críticas a esse tipo de profissional. Você já ouviu algo como “saber pouco de tudo é não saber nada de nada”?
Pois bem. Há até um certo fundo de verdade nisso. Se um profissional troca frequentemente de trabalho, mas não se aprofunda em nada, seu destino será exatamente esse: não saberá “nada de nada”.
Por outro lado, veja a tendência do mercado mudar fortemente nos últimos anos. Antes todos queriam espacialistas. Hoje, os profissionais mais valorizados são os que possuem uma visão abrangente da Engenharia de Software, mas conhecendo o que fazem profundamente.
No entanto, colocarei esses profissionais numa nova categoria…
Generalistas especialistas
Que diacho é um generalista especialista?
Após alguns anos de mercado, analisando vagas em grandes e pequenas empresas, notei uma tendência no perfil mais desejado por boas empresas.
É mais ou menos assim. O profissional deve:
- Ter pelo menos 5 ou 7 anos de experiência
- Dominar pelo menos 2 tecnologias
- Ter conhecimentos intermediários em várias tecnologias
- Conhecer o básico de todos os conceitos importantes da Ciência da Computação e Engenharia de Software
Obviamente esses valores e as estatísticas são uma média arbitrária da minha cabeça, mas serve bem para ilustrar meu ponto aqui. Vou traduzir isso em alguns princípios e estou certo que será útil para você.
1. Experiência
Os anos de experiência na verdade não são tão importantes em si mesmos. A questão toda está na maturidade do profissional.
As empresas e os próprios desenvolvedores querem alguém que agregue à equipe e não que seja um atraso. É uma realidade cruel para os novatos, mas a verdade é que hoje não importa muito se você é um gênio em matemática ou em programação. Os desafios mais comuns da Engenharia de Software estão em outras áreas, principalmente nas relações humanas. E, convenhamos, poucos recém-formados são habilidosos em trabalhar com pessoas.
Além disso, não importa se você sabe uma linguagem de programação de cabo a rabo. Resolver problemas complexos da via real exige uma carga de conhecimentos em diferentes áreas.
2. Especialização
Para entregar software no prazo e com qualidade, além de corrigir os problemas mais difíceis, o profissional deve dominar a tecnologia com que trabalha.
Porém, conhecer uma única tecnologia não é mais suficiente.
A grande maioria dos sistemas desenvolvidos hoje são web. De início, podemos dividir esses sistemas em back end e front end. Se você é da área, deve saber que em geral as tecnologias de um e de outro são completamente diferentes. Por isso, é comum hoje um bom profissional que domina .NET ou Java também dominar Javascript, HTML e CSS.
Note que não estou falando em conhecer um pouco de cada tecnologia, mas sim em ser altamente proficiente em várias delas.
3. Generalização
Com a grande variedade de tecnologias disponíveis, o profissional que conhece pelo menos em nível introdutório o funcionamento básico de cada uma, além dos conceitos que dão suporte a essas ferramentas, terá muito mais capacidade de escolher a solução mais correta e adequada para os diferentes desafios.
Isso parece contradizer o tópico anterior, mas não é bem assim. Se você domina pelo menos uns dois paradigmas de programação e tem bons fundamentos técnicos, provavelmente se dará bem com qualquer novidade. Este é o ponto: um generalista é muito mais adaptável a novos desafios.
As antigas guerras de “Ruby vs PHP”, “Python vs Perl”, “C++ vs Java” simplesmente acabaram, exceto para alguns que faltam em maturidade.
Hoje os bons profissionais sabem que não é preciso escolher uma linguagem definitiva. Você poderia usar todas ao mesmo tempo, se quiser. Aliás, em determinadas situações você deve usar um conjunto delas no mesmo projeto.
4. Visão abrangente
Primeiro, desenvolver software não é apenas digitar código. Tenha em mente que para programar bem você deve sim conhecer os fundamentos da Ciência da Computação.
Não vou menosprezar quem aprendeu por conta. Alguns conseguem. Mas não pense que nesta área você será um bom profissional sabendo apenas digitar comandos numa linguagem qualquer.
Estruturas de Dados, Sistemas Operacionais, Geometria, Cálculo, Estatística. Tenha certeza que, cedo ou tarde, disciplinas que lhe faltam poderão ser um empecilho para uma atividade de mais alto nível, a não ser que você queira fazer sistemas de cadastros e relatórios pelo resto da vida.
Segundo, desenvolver não é apenas programar bem. Se você tem alguma experiência em projetos, já deve saber que a programação em si é apenas uma parte de uma grande cadeia de comunicação, motivação, acordos, burocracia, egos e muito mais. Saber lidar com tudo isso é o que realmente irá levá-lo a algo maior.
O perfil do profissional ideal
Escutamos repetidas vezes que as empresas procuram o profissional com experiências nas tecnologias X, Y ou Z. Pode até ser verdade em muitos casos. Porém, quem já trabalha em TI há mais tempo sabe que bons profissionais, com bons fundamentos teóricos, podem aprender qualquer linguagem ou tecnologia.
Outra habilidade importante é a de realmente produzir coisas úteis. Pode parecer estranho, mas muitos profissionais com boa formação e conhecimento abrangente têm dificuldade em implementar ferramentas e sistemas que tenham algum valor para os clientes. Pode ser porque eles deem excessiva importância a minúcias técnicas ou não consigam entender o que o cliente realmente quer, mas seja qual for o motivo por detrás disso, o código que eles produzem é bom só para eles mesmos.
Já o profissional ideal é aquele que consegue compreender os usuários do sistema e implementar, tecnicamente da melhor forma, exatamente aquilo que o usuário precisa.
Por último, mas não menos importante, vou citar as habilidades interpessoais. Inclua no pacote boa capacidade de comunicação e uma personalidade agradável para então ter um profissional realmente “perfeito”.
É claro que na maioria das vezes essas questões de comunicação e relacionamentos são extremamente subjetivas. Elas acabam ficando de enfeite nas descrições de vagas e grande parte dos entrevistadores não dão importância a isso. Mas não se engane! A personalidade é um fator chave para o sucesso e fracasso de toda uma equipe.
Qual seria a personalidade ideal? Aquela que faz as pessoas se sentirem bem ao trabalhar com você. Um profissional que deixa o ambiente da empresa ruim gera um prejuízo incalculável. Porém, se os membros de uma equipe encontram em um profissional alguém com quem realmente desejam trabalhar, este profissional deveria ser mantido na empresa a todo custo.
Como chegar lá
Todo esse papo pode deixar você com um grande peso nas costas. Mas, como já disse, deixe a ansiedade para trás.
Se você é da geração Y ou, pior, da geração Z, mude sua disposição e saiba que todas as coisas boas levam tempo para serem construídas e tem um custo associado.
Primeiro, se você acha que sabe tudo, conscientize-se de que então não sabe nada.
Segundo, Aprenda conceitos e fundamentos sólidos. Não tente seguir todas as ondas e modinhas tecnológicas. Por exemplo, aprenda muito bem orientação a objetos antes de dizer que sabe C++, Java, Scala, Go. Aprenda o que é programação funcional antes de dizer que sabe Javascript. Aprenda sobre redes e protocolos antes de dizer que sabe desenvolver um sistema web.
Crie um planejamento de estudos. Quais são as coisas mais importantes e prioritárias para se aprender na sua área?
Estude frequentemente, não muito intensamente. Se você quer aprender bem Java, por exemplo, pode estudar para obter a certificação. Você vai precisar ler mais de 800 páginas. Faça um plano de estudos de 6 meses a 1 ano, dependendo do seu ritmo. Pode parecer muito, mas lembre-se que tudo leva tempo.
Conclusões
Você pode estar ansioso por alguma pressão externa. Então espero que este artigo tenha lhe acalmado.
Por outro lado, se você fica ansioso porque quer progredir muito rápido, tenha cuidado para não se decepcionar.
Se você acha que sabe muito mais do que pessoas mais velhas e mais experientes, talvez achando que a empresa não te reconhece, também tome cuidado. Faça entrevistas em empresas melhores para tirar a prova disso, pode ser uma lição de humildade.
Alguns programadores acham que são melhores que os chefes porque estes não conhecem tanto sobre uma certa linguagem ou certas novidades. Sim, em alguns casos pode ser verdade, mas na maioria das vezes falta maturidade em compreender os desafios diários que ele precisará enfrentar.
É o mesmo caso de tantos jovens que acham fácil programar e tentam empreender, só para depois perceber que não conseguem clientes o suficiente ou não dão conta das demandas técnicas e da gestão do negócio.
A experiência mostra que os inexperientes acham que tudo é fácil. A maturidade de um proporcional vem sempre acompanhada de sua capacidade de enxergar os desafios que ele precisa enfrentar e as consequências de suas decisões.
Enfim, não tenha pressa, estude sempre e aproveite todas as oportunidades que tiver para aprender e se relacionar com outros profissionais mais experientes.