

Estima-se que 2,5 quintilhões de bytes de dados são criados todos os dias, criados em sua maioria por usuários na web de forma desestruturada. em diferentes meios (texto, áudio, vídeo, etc.) e fontes (Facebook, Twitter, Youtube, etc.).
O potencial desses dados é gigantesco, mas os bancos de dados relacionais não são capazes de lidar com algo dessa natureza. Qual a solução?
A história dos dados
A forma como os dados são gerados, processados e armazenados mudou drasticamente ao longo das últimas décadas e mesmo em relação aos últimos anos.
Os primeiros cientistas da computação preocupavam-se em criar estruturas de dados otimizadas para armazenar a maior quantidade de informação, da forma mais eficiente possível. Os bancos de dados relacionais ajudaram bastante nessa tarefa.
Porém, o volume de dados que existe no mundo hoje simplesmente não cabe mais nesse modelo. Com a ascensão da Internet disponível, virtualmente, a todo mundo e com a popularização dos sistemas web, incluindo as Redes Sociais, temos hoje um número inimaginável de informação, que aumenta a cada dia.
Agora pare e imagine o potencial desses dados se devidamente analisados. As pesquisas de mercado tradicionais consideram uma população de algumas centenas ou, no máximo, milhares de pessoas para testar alguma tendência.
E se conseguíssemos analisar os dados comportamentais de milhões ou até bilhões de pessoas? A chance de identificar tendências em grupos mais específicos aumentaria enormemente.
O grande problema é que esse volume monstruoso de dados está distribuído em inúmeros locais e em geral não é estruturado para transportarmos tudo para tabelas.
Pense no Twitter. Milhares de pessoas ao redor do mundo postando comentários, críticas, reclamações em forma de um texto com no máximo 140 caracteres. Se pudéssemos analisar sobre o que as pessoas estão mais comentando hoje e se estão falando bem ou mal, teríamos uma enorme vantagem competitiva, não é mesmo? Poderíamos responder “em tempo real” aos consumidores de acordo com o que eles estão querendo.
Texto, som, vídeo, imagem. Há um enorme potencial em tudo isso em busca de uma informação relevante.
O que é Big Data?
Big Data é um termo cunhado por Budhani em 2008 para descrever qualquer conjunto de dados que seja inviável de manipular por uma ferramenta tradicional em um tempo razoável.
Obviamente isso é um tanto vago, mas já existem algumas definições mais específicas.
Os V’s do Big Data
Ao contrário do que o termo pode levar-nos a pensar, Big Data não é apenas sobre o volume de dados. Em tese, um SGBDR tradicional pode tratar quantidades imensas de dados. Big Data envolve outras características relacionadas com velocidade e variedade.
Procurando definir o que é Big Data, alguns pesquisadores chegaram a um conceito de múltiplos atributos. Isso ficou conhecido como os 3 V’s do Big Data: Volume, Velocidade e Variedade.
Entretanto, o amadurecimento da tecnologia deu origem a uma definição mais completa, com 5 V’s: Volume, Velocidade, Variedade, Valor e Veracidade
Confira na imagem abaixo:
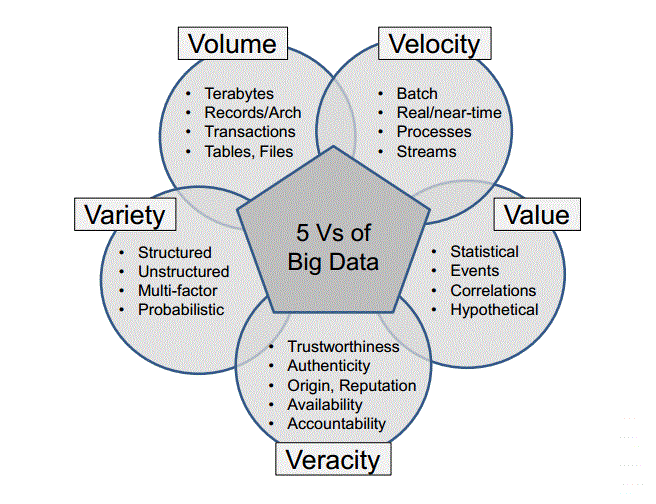
Volume
Big Data envolve uma quantidade de dados que começa na casa dos terabytes e chaga até os petabytes. Note que enquanto escrevo esta informação já pode estar desatualizada!
Velocidade
As informações precisam ser transmitidas, processadas e retornadas em tempo hábil para o negócio. Pense na busca do Google, ela precisa “ler a internet” em alguns milissegundos. Ou você usaria o Google se cada pesquisa levasse horas ou dias?
Variedade
Ao contrário dos sistemas de informação mais tradicionais, Big Data gira em torno de uma grande variedade de dados não estruturados e não normalizados.
Muitas informações podem ser obtidas através de processamento de vídeos do youtube, tweets, arquivos de log e páginas de blog.
Eu sei que você já deve estar cansado de eu usar o Google como exemplo, mas farei novamente. Já viu a legenda automática do YouTube? Houve um bom avanço nos algoritmos de análise de áudio, não é? Já pensou em como o Google ordena os resultados da pesquisa, priorizando o conteúdo mais adequado para os termos inputados?
Trabalhar com SEO nada mais é do que tentar influenciar os algoritmos de Big Data do Google!
Valor
Com o amadurecimento das soluções de Big Data, notou-se que as três características já apresentadas não eram razão suficientes para a utilização desta tecnologia.
É necessário que as informações extraídas da massa de dados proporcionem um benefício tangível.
Por exemplo, se uma empresa consegue identificar através de análises estatísticas certas tendências dos consumidores, ela poderá obter uma grande vantagem em relação aos seus concorrentes.
Veracidade
Desde que alguns institutos passaram a usar dados de redes sociais para verificar tendências, surgiu uma nova versão de ataque digital que procura manipular os resultados.
Vou dar um exemplo. Ouvi recentemente que foram criados bots (robôs) para gerar milhares de tweets e postagens na Internet sobre certo candidato a cargo político. O objetivo é fazer parecer que o candidato tem popularidade, sendo “o candidato mais comentado na internet”.
Uma preocupação que tem faltado nas implementações de Big Data é justamente verificar se os dados são oriundos de fontes confiáveis e se os mesmos são autênticos.
Não vou aprofundar-me nesse assunto, mas continuando com o exemplo, uma boa implementação de contagem de tweets poderia eliminar as mensagens repetidas ou muito parecidas. Isso porque spammers são capaz de gerar frases aleatórias com variações de palavras. Portanto a mesma técnica que filtros de spam utilizam deveria ser aplicada nesse caso.
Por quê Big Data?
Até aqui você já deve ter compreendido alguns conceitos básicos sobre Big Data. Porém, ao mesmo tempo, pode estar se perguntando essa tecnologia não teria seu uso limitado a empresas altamente técnicas como o Google.
Em teoria, sobre tudo o que se pode fazer estatística pode se beneficiar de Big Data.
Vejamos agora algumas aplicações reais de grandes e pequenas empresas.
Vendas
O Walmart, por exemplo, adotou Big Data desde muito cedo. Os dados de dez diferentes sites foram consolidados num cluster Hadoop, migrados a partir de bases Oracle e outras fontes de dados.
Além de diminuir o tempo das buscas o Walmart é capaz de verificar se um amigo seu lhe enviou informações sobre um determinado produto em uma rede social e então lhe mandar um e-mail com uma promoção daquele produto.
Ele também pode lhe indicar produtos de acordo com o perfil dos seus amigos no Facebook, de modo que você possa dar um presente adequado.
Telecom
Algumas empresas de Telecom usam Big Data para traçar perfis dos consumidores, unindo padrões de ligação, envio de mensagem e participação em redes sociais. Eles conseguem então descobrir quais consumidores estão mais propensos a trocar de operadora.
Esportes
No campo dos esportes, há várias iniciativas de monitoramento dos atletas. Isso permitirá a análise do desempenho de um time e de cada indivíduo, possibilitará encontrar tendências, prever resultados e até criar jogos mais reais com as características dos times verdadeiros.
Saúde
Na saúde, os pesquisadores poderão prever com mais precisão problemas de saúde baseando-se em históricos hospitalares.
Hoje já existem estudos sobre a coleta de informações de respiração e batimentos cardíacos de bebês nascidos prematuros e o uso de Big Data para identificar padrões de infecção. Isso possibilitará identificar antecipadamente quando um bebê realmente está com infecção antes dos sintomas mais visíveis aparecerem e, consequentemente, aplicar um tratamento mais efetivo.
Trânsito
No Japão, um aplicativo baseado em Big Data está ajudando a melhorar trânsito de uma cidade ao coletar informações de 12 mil táxis e vários sensores.
O serviço consegue analisar 360 milhões de informações sobre o trânsito instantaneamente para retornar a melhor rota naquele horário para o motorista. Com bancos de dados relacionais, o processamento levava vários minutos.
O que realmente é Big Data?
Parafraseando um outro artigo, “no fundo, no fundo, Big Data não se trata de dados nem de tamanho”. Também não se trata de novidades tecnológicas ou descobertas científicas.
Big Data é uma nova forma de ver o mundo, de usar estatísticas e de tomar decisões de negócio.
Uma metáfora seria como a descoberta do microscópio. Uma vez que se consegue enxergar as coisas numa escala completamente diferente de antes, novas descobertas inevitavelmente irão surgir.
A análise criteriosa de um grande volumes de dados é uma tendência que vai continuar e logo se expandirá para mais e mais esferas da vida humana.
Big Data é apenas mais uma modinha?
Algumas pessoas acham que Big Data é apenas mais uma moda tecnológica.
Como toda moda, existe um ciclo onde a princípio todos estão falando sobre aquilo e tem uma expectativa muito alta, depois começam a perceber que o investimento não está trazendo todos os benefícios imaginados, alguns desistem e outros persistem e começam a usar a tecnologia de forma mais adequada e ao final atingem um grau mais real de aproveitamento.
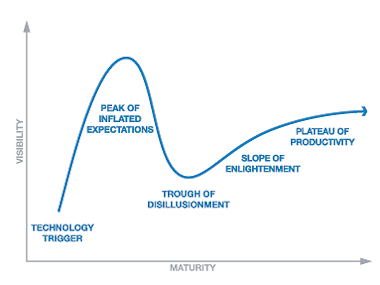
Certamente os termos e as tecnologias podem mudar, mas é verdade também que a ideia principal está aí para ficar.
Big Data não é a mesma coisa que Data Warehouse ou Business Intelligence?
Quem conhece um pouco sobre Data Warehouse ou Business Intelligence pode ter encontrado muitos pontos em comum com o que foi apresentado sobre Big Data. Muitos, inclusive argumento que é a mesma coisa. Será?
Por um lado, podemos dizer que a ideia principal é a mesma, a saber, processar um grande volume de dados para ajudar em decisões de negócios e detectar padrões.
Por outro lado, as tecnologias de BI e DW são mais conservadores no que diz respeito às técnicas, tecnologias e estruturas de dados. O foco delas é processar e consolidar os dados estruturados das empresas em uma base de dados somente-leitura separada dos bancos de dados principais dos sistemas a fim de obter estatísticas relevantes.
Já Big Data tem por objetivo unir fontes heterogêneas, privadas e públicas, geralmente em bases NoSQL ou mesmo em arquivos, com dados modificáveis. Big Data também é usado diretamente “em produção”, provendo informações diretamente para os usuários. Os fundamentos também são diferentes, pois Big Data lida especialmente para processamento distribuído, como veremos em breve num artigo sobre MapReduce.
Quais são as tecnologias relacionadas com Big Data?
Não entrarei em detalhes, pois pretendo escrever outros artigos sobre essas tecnologias. Vou simplesmente citar as mais comuns que envolvem o ecossistema do Hadoop, de longe a solução Big Data mais conhecida e também usada como base para outras soluções comerciais.
Hadoop
É uma implementação opensource do framework MapReduce. O Hadoop é um projeto mantido pelo grupo Apache.
Ele é capaz de coordenar tarefas executadas processamento distribuído e paralelo de grandes conjuntos de dados em qualquer quantidade de nós de um cluster.
O Hadoop é implementado em Java, sendo executado numa JVM. Você pode escrever um programa para executar no Hadoop usando a API disponibilizada em jars ou no Maven, inclusive usando sua IDE predileta.
No entanto, Java não é o limite. O Hadoop nada mais é do que uma base de uma pilha de tecnologias, incluindo linguagens de mais alto nível para fins específicos.
HDFS
O Hadoop Distributed File System é um sistema de arquivos distribuído de alta velocidade usado no Hadoop.
YARN
Trata-se de um framework para agendamento de tarefas e gerenciamento do cluster.
HBase
Um banco de dados NoSQL com suporte a dados estruturadas e tabelas grandes.
Hive
O Hive é um tipo de linguagem SQL (HiveQL, para ser mais exato) próprio para realizar consultas em grandes quantidades de dados distribuídos.
Mahout
Este é um projeto que procura unir Inteligência Artificial com Big Data, falando especificamente de Aprendizado de Máquina.
Pig
Pig é uma linguagem de programação de alto nível que facilita na criação de tarefas e análise de dados distribuídos, com execução em paralelo.
Bem, eu sei que você pode ser especialista em “programação porca”, mas não é disso que se trata o Pig. Tá… todo mundo aqui no Brasil já fez essa piada, mas não pude perder a oportunidade! 😉
ZooKeeper
Para manter todos os bichos do Hadoop em suas jaulas é necessário alguém para administrar tudo.
O ZooKeeper é um serviço centralizado para manter a configuração, dar nomes, prover sincronização e agrupamento de serviços.
Mas quem vai operar tudo isso?
Big Data trouxe também um novo tipo de profissional ao palco: o Cientista de Dados.
Uma breve pesquisa sobre esse termo vai trazer muitos resultados, demonstrando que é uma carreira em alta no momento.
Os cientistas de dados devem unir diversas habilidades:
- Ser bom em estatística e matemática para analisar corretamente os dados;
- Dominar as bases da Ciência da Computação para implementar devidamente as soluções, que geralmente incluem algum tipo de programação e entendimento da arquitetura distribuída; e
- Conhecer o negócio da empresa para gerar benefícios tangíveis com os resultados do seu trabalho.
Considerações finais
Sendo uma moda ou não, as empresas estão investindo pesadamente e obtendo resultados concretos com Big Data. Quanto antes uma empresa obtiver os benefícios em potencial de uma solução Big Data, mais ela terá chances de aumentar sua participação no mercado.
Os profissionais que mais cedo dominarem essa tecnologia também terão mais chances de destacar-se nesse nicho de mercado.
Como em toda mudança, os que chegarem por último terão que se contentar com as sobras.
A maior consideração quanto a isso é não entrar no frenesi de implementar Big Data por um fim em si mesmo, nem criar expectativas irreais sobre as tecnologias.
Torna-se necessário então compreender o cenário atual para avaliar cautelosamente o caminho adequado para um investimento em Big Data.
Além disso, voltando ao exemplo do microscópio, a nova visão de mundo proporcionada pela análise de enormes massas de dados deve ser suplementar e não substituta da visão da realidade dos negócios e da realidade humana.

