Este artigo é o Capítulo IV da minha monografia de Especialização em Engenharia de Software. Embora seja um referencial teórico e não acrescente nada de novo, espero que o possa ser útil de alguma forma para o leitor.
Introdução
A estimação de software é fundamental para qualquer projeto. Estimativas de custo, esforço e prazo são geralmente demandadas por clientes e o gerente do projeto precisa ter uma base para o planejamento e para tomar decisões no decorrer do projeto. A estimação também contribui para um maior entendimento do problema e provê um horizonte para a conclusão do projeto ou da iteração.
Existem diversas técnicas, abordagens e modelos de estimação. Este capítulo apresenta alguns deles com a finalidade de prover ao leitor uma visão geral sobre o tema.
Definições relacionadas à estimação
Estimar é prover uma visão do projeto clara o suficiente para que a gerência possa tomar boas decisões de como gerenciar o projeto para que o mesmo atinja seus objetivos (McConnell, 2006). Um dos propósitos da estimação é determinar se esses objetivos são tangíveis o suficiente para que o mesmo possa ser gerenciado de forma a atingir esses objetivos (Pressman, 2009, p. 519).
Boas estimativas são as que levam a decisões de negócio corretas (McConnell, 2006). A organização sofre prejuízo ao executar um projeto onde o orçamento e os esforços reais ultrapassam os valores estimados em uma determinada escala. Portanto, boas estimativas seriam aqueles que fornecessem a aproximação necessária para que o orçamento e o esforço fossem estabelecidos com uma margem adequada.
McConnell (2006) define boas estimativas do ponto de vista estatístico como aquelas que variam em 25% ou menos, durante pelo menos 75% das vezes. O critério arbitrário do autor reforça o conceito de que boas estimativas são as que proporcionam boas aproximações suficientes para que a maioria das decisões sobre projetos estejam corretas.
Uma estimativa não é uma medida, mas uma suposição sobre algo que se espera ser verdadeiro. Técnicas e modelos matemáticos podem dar a falsa impressão de acurácia, mas previsões sobre o software são sempre baseadas em julgamentos subjetivos com base em uma definição abstrata do sistema.
Estimativas não devem ser ajustadas para se adequar ao objetivo de negócio da empresa ou do cliente, tal como para atender um prazo arbitrário. O esforço de desenvolvimento e a complexidade do software não mudam devido a esses aspectos. Quando é necessário entregar um software antecipadamente, devem-se ajustar outras variáveis para que o esforço necessário seja atingido em um tempo menor.
Uma estimativa não é um compromisso (McConnell, 2006). Os executivos de uma organização geralmente querem um compromisso e um plano para alcançar um objetivo de negócio. Embora o compromisso e o plano possam ser baseados em estimativas, é importante diferenciar os conceitos.
Além disso, a estimação deve considerar diversas influências sobre o desenvolvimento de software. Ao se estimar devem ser considerados fatores relacionados ao problema, ao cliente, ao ambiente de desenvolvimento e às pessoas envolvidas, os quais influenciam diretamente no projeto de software.
Segundo McConnel, a atividade de estimação seria análoga a uma arte ao invés de um processo científico (McConnell, 2006). Embora técnicas e modelos forneçam uma abordagem consistente para a estimação, o conhecimento, a experiência e as habilidades do estimador são determinantes para a qualidade das estimativas.
Grau de incerteza das estimativas
As estimativas possuem grau de incerteza variável no decorrer do projeto (McConnell, 2006). Elas são incertas por natureza (Pressman, 2009, p. 520), mas a incerteza pode diminuir ao passo em que medidas do projeto são coletadas e o problema conhecido mais detalhadamente. Este pensamento é exemplificado na Figura 6, onde Cohn (2006, p. 4) apresenta o Cone da Incerteza.
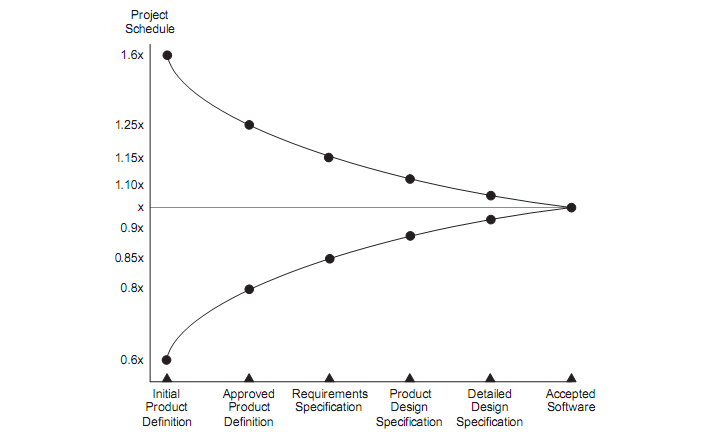
Figura 6 – Cone da Incerteza (Cohn, 2006, p. 4)
As estimativas podem ser analisadas do pondo de vista probabilístico. Ao invés de um valor absoluto, considera-se uma faixa de valores com maior probabilidade de conter o valor real. No início do projeto a incerteza atinge seu ápice, mas diminui na medida em que as tarefas são concluídas, os riscos mitigados e o gerente pode avaliar o que realmente foi realizado em contraste com o que foi previamente planejado. A incerteza é mínima ao final do projeto, quando todas as atividades estão concluídas e o esforço necessário para completá-las contém o valor que reflete a realidade.
Entretanto, o grau de incerteza representado pelo Cone da Incerteza (Figura 6) reflete a menor incerteza possível num determinado ponto do projeto. McConnell (2006) afirma que o comum é a incerteza ser maior do que a apresentada no gráfico, principalmente em projetos onde não se tomam as precauções necessárias em cada fase através de um gerenciamento adequado.
Barreiras e influências na estimação de software
Não existe uma forma de estimação determinística. Esforços e recursos foram despendidos para criar e aperfeiçoar técnicas e modelos de estimação, mas características como mutabilidade dos requisitos e a intangibilidade do software os tornam inerentemente difícil de estimar.
Barreiras na elicitação de requisitos fazem parte dos principais fatores que tornam a estimação difícil. Como apresentado no capítulo II, os requisitos mudam ao longo do tempo. Muitos tipos de domínios sofrem mudanças muito rapidamente, outros são muito complexos, há casos onde os usuários não conseguem definir suas necessidades ou o conhecimento está fragmentado de tal forma que não é possível identificar com precisão o que deve ser desenvolvido.
As características do software também dificultam a tarefa de estimação. Identificar a solução completa para um problema é um desafio. O software é um produto abstrato, desenvolvido em um processo diferente da engenharia convencional, pois cada software é único. Tudo isso torna desafiadora a tarefa de prever o esforço de desenvolvimento.
Além disso, os projetos de software são imprevisíveis e ocorrências podem invalidar a estimação realizada. Brooks (1975) afirma que “nossas técnicas de estimativa são mal desenvolvidas […] elas não refletem um pressuposto não mencionado, que não é muito verdadeiro, isto é, de que tudo irá correr bem.” Brooks acrescenta que a pressão externa pode resultar em estimativas tendenciosas e ruins, pois “frequentemente falta aos gerentes de software firmeza de fazer o pessoal esperar por um bom produto”.
Imprevistos podem ocorrer de diversas formas no decorrer do projeto. Alguns tipos de imprevistos incluem aspectos já discutidos neste estudo sobre o software e os requisitos. Pressman (2009, p. 520) identifica e classifica uma série de fatores que impactam no custo e no esforço de desenvolvimento, conforme a tabela a seguir.
Tabela 3 – Fatores que impactam no desenvolvimento de software (Pressman, 2009, p. 520)
| Fatores |
Exemplos |
| Humanos |
Pedidos de demissão, problemas pessoais, habilidades dos indivíduos. |
| Ambientais |
Dificuldade de comunicação com cliente ou entre a equipe de desenvolvimento, mudanças no negócio, no escopo ou no domínio. |
| Políticos |
Mudanças em leis, nas políticas da empresa. |
| Técnicos |
Ferramentas de desenvolvimento apresentam problemas ou possuem limitações difíceis de contornar, mudanças e restrições tecnológicas. |
Existem problemas que, quando presentes em um projeto, influenciam negativamente na estimação, a qual dificilmente refletirá a realidade. McConnell (2006) identifica alguns desses problemas, os quais estão descritos na tabela abaixo.
Tabela 4 – Influências negativas sobre a estimação (McConnell, 2006)
|
|
| Processo de desenvolvimentocaótico |
Ocorre quando há falha em uma ou mais partes do projeto. Por exemplo: requisitos não elicitados adequadamente desde o início, falta de envolvimento dos usuários na validação dos requisitos, práticas de codificação ruins, inexperiência da equipe, plano de projeto incompleto, abandono do plano nos momentos de pressão, falta de gerenciamento automatizado do código. |
| Requisitos instáveis |
Mudanças são esperadas, mas os requisitos precisam estar bem definidos em algum momento, caso contrário a estimação não será adequada nem mesmo em fases avançadas do projeto. |
| Atividades omitidas |
Umas das fontes mais comuns de problemas é o esquecimento de incluir atividades essenciais. Alguns exemplos comuns são: instalação do sistema, conversão de dados, adequação e uso de bibliotecas de terceiros, ajuda ao usuário, interfaces com sistemas externos. Além disso, alguns requisitos não funcionais também são esquecidos, tais como desempenho, confiabilidade, escalabilidade, segurança, entre outros. |
| Otimismo sem fundamento |
Desenvolvedores tendem a gerar estimativas otimistas com fator de vinte a trinta por cento, em média. |
| Subjetividade e tendência pessoal |
Tendências pessoais conscientes ou inconscientes do estimador geram erros de estimação para mais ou para menos. |
| Estimativas informais |
Estimativas repassadas de desenvolvedores para seus superiores, sem que haja tempo hábil para avaliar criteriosamente a situação, provavelmente serão bem diferentes da realidade. |
| Precisão não necessária |
O termo precisão não deve ser confundido com acurácia. Acurácia significa estar próximo da realidade, enquanto precisão está mais relacionada ao nível de detalhamento, por exemplo, o número de casas decimais de um resultado. Estimativas demasiadamente precisas e detalhadas não necessariamente são verdadeiras. Uma estimativa com precisão de horas não tem utilidade. Uma boa prática seria estimar com base em semanas, meses ou o que for adequado para o tamanho do projeto, resultando numa maior acurácia. |
Além disso, as estimativas também são influenciadas por características do projeto e da equipe. A influência pode ser positiva ou negativa, dependendo de cada característica. McConnell (2006) cita quatro características do projeto e da equipe descritas na tabela a seguir.
Tabela 5 – Características do projeto que influenciam estimativas (McConnell, 2006)
|
|
| Tamanho do projeto |
O esforço por linha de código aumenta proporcionalmente ao tamanho do projeto. É importante descobrir o porte do projeto para depois ajustar as estimativas individuais. |
| Tipo de software |
O rendimento da equipe varia dependendo da área para a qual o software está sendo desenvolvido. Por exemplo, softwares desenvolvidos para uma intranet chegam a ter um rendimento vinte vezes maior do que softwares construídos para a aeronáutica. |
| Fatores pessoais |
Estudos mostram que o desempenho pode variar numa escala de dez vezes entre indivíduos. As estimativas devem ser ajustadas conforme o desempenho dos desenvolvedores envolvidos. |
| Linguagem de programação ou tecnologias |
Ao usar o número de linhas de código como base para as estimativas, deve-se usar um fator de ajuste dependendo da linguagem utilizada. O mesmo pode ser estendido para outras tecnologias envolvidas. |
Pressman (2009, p. 525) também destaca algumas influências que devem ser consideradas na estimação. Segundo o autor, mesmo que o software a ser estimado fosse relativamente estático em relação ao ambiente e aos requisitos, existem fatores externos que influenciam diretamente na qualidade das estimativas, tais como:
- o grau de precisão com que o planejador estimou o tamanho do produto a ser construído;
- a precisão para transformar a estimativa de tamanho em esforço humano, tempo e custo;
- experiência do gerente;
- acesso a boas informações históricas.
Enfim, a estimação é uma atividade desafiadora que possui diversas influências e dificuldades intrínsecas oriundas das barreiras do desenvolvimento de software e da natureza dos requisitos, das várias influências e das características do projeto, além do risco de problemas que podem ocorrer durante o projeto.
Princípios gerais de estimação
Existem princípios que podem ser aplicados a qualquer forma de estimação. Embora as diferentes técnicas e modelos de estimação sejam diferentes em diversos aspectos e aplicáveis em diferentes contextos, a natureza das estimativas permanece a mesma.
Quanto mais cedo ocorrer a estimação, piores serão as estimativas (Pressman, 2009, p. 524). A estimação antecipada de todo o software tende a gerar estimativas piores do que em casos onde elas são feitas em fases posteriores do projeto (Pressman, 2009, p. 520). Embora muitas vezes seja necessário estimar todo o software, é importante refazer a estimação quando se deseja obter uma posição atualizada sobre o estágio de desenvolvimento.
Além disso, informações de projetos semelhantes já completados tendem a deixar as estimativas melhores. Dessa forma, é possível prever com mais exatidão o esforço necessário ao se basear em experiências anteriores.
A decomposição do projeto e do software em unidades menores também ajuda na estimação. Isso facilita ao estimador manter o foco e ter uma visão mais clara do que ele está estimando. Além disso, é mais fácil encontrar informações históricas de componentes de software semelhantes já desenvolvidos.
Estimativas de componentes do software podem ser feitas utilizando medidas relativas (Cohn, 2006, p. 34). Em técnicas que utilizam este recurso, atribui-se um valor relativo a cada componente ou funcionalidade do sistema. Então a estimativa final é calculada baseando-se em dados de projetos semelhantes ou com base no que já foi desenvolvido do projeto corrente. Dessa forma, não é necessário refazer as estimativas individuais dos componentes do sistema no decorrer do projeto, sendo necessário apenas ajustar o fator usado para calcular a estimativa final de acordo com as avaliações do projeto.
A qualidade de uma estimativa pode ser verificada utilizando um segundo método de estimação. Quando o estimador está incerto sobre uma estimativa e deseja uma certeza maior sobre a mesma, pode-se realizar uma nova estimação através de outra técnica ou modelo a fim de averiguar se a primeira estimativa era confiável.
Entretanto, não é recomendado investir esforço demasiado na estimação. Esforços exagerados em melhorar as estimativas podem resultar num efeito contrário ao esperado, gerando distorção nos valores obtidos. Cohn (2006, p. 54) fez um levantamento sobre os esforços para obter melhores estimativas e percebeu que, a partir de um determinado momento, quanto mais tempo é investido nessa tarefa, mais o resultado estará longe da realidade (Figura 7).
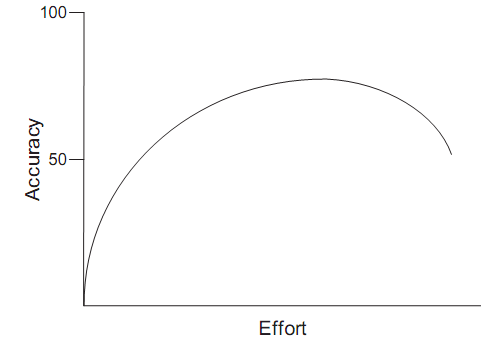
Figura 7 – Gráfico de Escorço x Acurácia das Estimativas (Cohn, 2006, p. 54)
Estimação indireta
Algumas das técnicas de estimação são indiretas (McConnell, 2006). Por exemplo, dividir o sistema em componentes e estimar baseando-se nas características dos componentes ou estimar através de uma classificação das funcionalidades utilizando lógica fuzzy (categorizando cada funcionalidade como muito pequena, pequena, média, grande ou muito grande) são formas indiretas de estimação. Após a estimação dos elementos do software calcula-se a estimativa final de acordo com a técnica utilizada.
Aplicabilidade das técnicas e modelos de estimação em processos
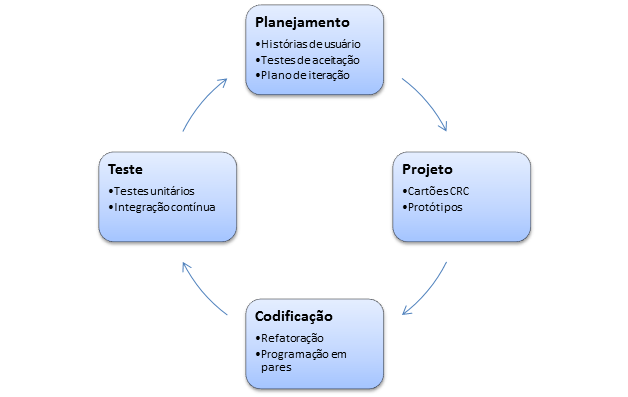
A escolha de uma técnica ou modelo de estimação em um projeto pode ser definida com base no processo de desenvolvimento adotado. Características do processo podem inviabilizar ou recomendar o uso de determinada técnica ou modelo de estimação. Processos ágeis que utilizam histórias de usuário para ilustrar as funcionalidades do sistema dificultam a aplicação de técnicas de estimação que dependem de um modelo de análise e design.
Técnicas de estimação que exigem detalhamento do sistema são mais recomendados para processos disciplinados ou que exigem maior burocracia. Em geral, essas técnicas de estimação partem do modelo de análise procurando antecipar o tamanho e a complexidade do software (Pressman, 2009, p. 357). O modelo de análise deve estar detalhado o suficiente para permitir que seus elementos sejam estimados. Como os processos burocráticos dão grande importância ao planejamento antecipado como um dos fatores mais críticos para o sucesso ou a falha de um projeto (Pressman, 2009, P. 519) então uma técnica de estimação mais detalhada torna-se adequada.
Por outro lado, técnicas empíricas baseadas em julgamento humano de funcionalidades ou características de alto nível de um software são recomendadas quando a organização adota processos com pouca burocracia, tal como processos ágeis.
Estimação em processos ágeis
A estimação nos processos ágeis é, em geral, baseada em histórias de usuário (Cohn, 2006, p. 34). A unidade de medida comumente utilizada é a story point (ponto de história), que indica o tamanho de uma história de usuário que está no backlog do produto, numa escala definida para o projeto em questão. Os story point atribuídos às histórias de usuários possuem valor relativo entre as várias histórias, com o objetivo de permitir a comparação.
Uma história de usuário é detalhada em tarefas individuais para a equipe de desenvolvimento no início da iteração em que foi selecionada para ser implementada. O esforço das tarefas é então estimado em horas. É recomendado que uma tarefa não tenha duração de mais de um dia de trabalho.
A estimação em processos ágeis é feita pela equipe. Os agilistas enfatizam que a estimação é mais bem feita pelos indivíduos que efetivamente criam o software, ao invés de um analista ou gerente.
Além disso, a estimação deve ser em equipe, de modo que todos ou a maioria concorde com cada estimação. Deve-se evitar que um membro influencie o outro na estimação inicial, pois um membro da equipe poderia ter receio de ter uma opinião muito diferente sobre determinadas estimativas. Cada membro da equipe teria o potencial de apresentar uma perspectiva sobre um determinado requisito que os demais não conseguiram visualizar. Dessa forma, haveria uma verificação coletiva de cada estimativa.
Modelo básico da atividade de estimação
A atividade estimação pode ser dividida em três tarefas básicas, independente do modelo ou técnica utilizada (McConnell, 2006).
Primeiramente, deve-se realizar a escolha da técnica de estimativa considerando o tamanho e o estágio atual do projeto, o processo de desenvolvimento (iterativo, sequencial, evolutivo) e a acurácia possível.
Em seguida, o estimador deve contar, computar e julgar de forma adequada os elementos que servirão como base das estimativas, tais como linhas de código, horas de trabalho ou pontos de história;
Finalmente, deve-se calibrar a contagem realizada. Isso é feito utilizando dados históricos de projetos passados ou de iterações anteriores do mesmo projeto e avaliando características internas e externas que influenciam o projeto. Desse modo, a contagem pode ser realmente considerada uma estimativa.
Técnicas e modelos de estimação
Estimação orientada a objetos
Sistemas orientados a objetos podem ser estimados através de modelagem orientada a objetos, como a UML (Unified Modeling Language). Atribui-se valores a cada objeto do sistema e, assim, pode-se chegar a uma estimativa geral.
Algumas medidas sugeridas por Pressman (2009, p. 506) são:
- número de scripts de cenários de interação entre usuário e o sistema;
- número de classes importantes e independentes do sistema;
- número de classes de apoio não relacionadas ao domínio (banco de dados, interface com usuário);
- número de classes de apoio relacionadas ao domínio;
- número de subsistemas.
Estimação orientada a casos de uso
É possível utilizar casos de uso para estimar um software. As estimativas de cada caso de uso possibilitariam planejar o projeto com um todo.
Entretanto, como casos de uso são muito abstratos e pessoas diferentes trabalham em diversos níveis de abstração. Não há parâmetros para definir uma medida padrão para o esforço necessário para implementar um dado caso de uso (Pressman, 2009, p. 507). Em decorrência disso, a estimação com casos de uso não é recomendada, sendo pouco utilizada.
Estimação orientada a componentes
Um sistema pode ser dividido em componentes de acordo com as características de seus componentes. Por exemplo, um sistema com arquitetura para a web poderia ter seus elementos classificados em páginas dinâmicas, páginas estáticas, tabelas de banco de dados, relatórios e regras de negócio (McConnell, 2006). Cada conjunto representa um componente, cujos elementos são semelhantes.
Dados históricos classificados de acordo com os tipos de componentes ou o julgamento de um especialista podem ser usados para estimar o número de linhas de código ou esforço necessário para desenvolver cada componente.
Estimação baseada no julgamento de um especialista
Esta técnica consiste em dividir o desenvolvimento do aplicativo de software em tarefas utilizando uma granularidade adequada, isto é, dividindo tarefas grandes, de longa duração ou complexas, em menores e utilizando faixas de estimativas com melhor e pior caso. Esses valores são usados para derivar uma estimativa final que possuiria grande probabilidade de sucesso.
Na medida em que o projeto evolui, o estimador compara os dados obtidos das tarefas já concluídas com as estimativas originais e calcula o erro relativo, ajustando os valores estimados para as tarefas futuras.
Através dessa técnica, um estimador que realiza seu trabalho de forma estruturada e não apenas intuitiva pode conseguir bons resultados (McConnell, 2006). Apesar de ser totalmente empírico, este é o método mais utilizado nas organizações.
Estimação por analogia
Consiste em estimar um projeto baseando-se em outro com arquitetura semelhante já concluído, ou seja, que possui dados reais sobre as tarefas realizadas.
Esta técnica pode gerar grandes erros se usado de forma indevida (McConnell, 2006). Primeiramente é necessário possuir dados precisos e detalhados sobre o projeto antecessor. Uma boa prática seria construir as novas estimativas como uma porcentagem em relação ao projeto anterior, comparando o tamanho de ambos. Ainda assim é necessário considerar diferenças importantes, tais como tecnologias diferentes, tamanhos muito distintos, equipe diferente, etc.
Estimação por Ponto de Função (Function Point)
A técnica de estimativa por ponto de função se propõe a medir o tamanho das funcionalidades de um sistema (Pressman, 2009, p. 357). Através de uma lista dos elementos do software a serem construídos, avaliações da complexidade desses elementos e dados históricos, seria possível estimar:
- custo e esforço do desenvolvimento;
- quantidade de erros encontrados nos testes;
- número de componentes e linhas de código projetadas no sistema.
As entradas necessárias para realizar a estimação são:
- número de entradas externas: entrada de dados pelo usuário ou por outra aplicação;
- número de saídas externas: saída que fornece informação ao usuário (relatórios, telas, etc.);
- número de consultas externas: chamada on-line com resposta imediata, como uma chamada de serviço por outra aplicação;
- número de arquivos lógicos internos: quantidade de agrupamentos de dados, tal como tabelas, arquivos de dados, entre outros;
- número de arquivos de interface externa: dados externos acessados pela aplicação.
Cada entrada é extraída de modelo da aplicação. A partir dos dados obtidos, cada elemento é contado, avaliado e categorizado em níveis de complexidade, geralmente de forma subjetiva, como simples, médio ou complexo. O resultado é utilizado para calcular uma contagem total dos pontos, conforme a figura abaixo:
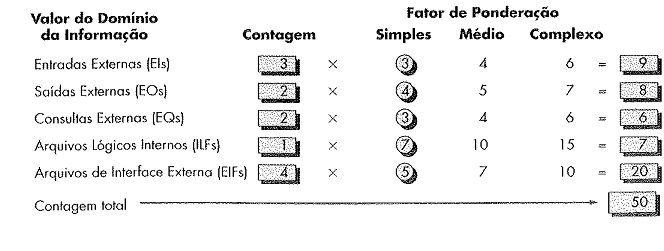
Figura 8 – Exemplo de Estimativa por Ponto de Função (Pressman, 2009, p. 359)
Alguns valores de ajuste (Fi) são definidos baseados em respostas com valores de “0” (não importante) até “5” (absolutamente essencial) às catorze descritas na tabela a seguir:
Tabela 6 – Fatores de ajuste da técnica de estimação por pontos de função (Pressman, 2009, p. 357)
|
|
| 1 |
O sistema precisa de backup? |
| 2 |
Modos de transferência de dados específicos são usados para importar ou exportar dados? |
| 3 |
Existe processamento distribuído? |
| 4 |
O desempenho é crítico? |
| 5 |
O sistema funcionará em um ambiente operacional existente, intensamente utilizado? |
| 6 |
O sistema requer entrada de dados online? |
| 7 |
A entrada online exige que a transação seja construída por várias telas ou operações? |
| 8 |
Os arquivos lógicos internos são atualizados online? |
| 9 |
As entradas, saídas, arquivos ou consultas são complexos? |
| 10 |
O processamento interno é complexo? |
| 11 |
O código foi projetado para ser reusado? |
| 12 |
A conversão e instalação estão incluídas no projeto? |
| 13 |
O sistema está projetado para instalações múltiplas em diferentes organizações? |
| 14 |
A aplicação está projetada para facilitar modificações no uso do usuário? |
Ao final, aplica-se a seguinte equação para obter o valor de pontos de função:
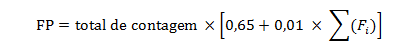
Figura 9 – Equação para obter o resultado da métrica por pontos de função
Os níveis de complexidade e os fatores de ajuste são valores subjetivos, pois dependem completamente da experiência e intuição do estimador. Entretanto, eles mesmos podem ser ajustados através de um histórico de dados colhidos em projetos anteriores (Pressman, 2009, p. 505).
A quantidade de linhas de código de um sistema (LOC – Line of Code) pode ser derivada a partir dos pontos de função. Através de estimativas grosseiras da quantidade de linhas de código da linguagem de programação escolhida por ponto de função, a quantidade total de linhas de código é calculada, através de simples multiplicação, e utilizada para prever o tamanho do sistema.
Modelo COCOMO II
COCOMO (Constructive Cost Model) é um modelo para estimar custo, esforço e cronograma durante o planejamento de projetos de software. Ele foi inicialmente publicado por Barry Boehm em 1981 e posteriormente foi lançada uma versão atualizada denominada COCOMO II, em 1995, refletindo a dramática evolução das práticas de desenvolvimento de software (CSSE).
O modelo COCOMO II possui um programa de afiliados que investem técnica e financeiramente no seu desenvolvimento, incluindo grandes empresas e laboratórios de pesquisa. Ele é um modelo aberto, isto é, pode ser usado por qualquer organização, e faz uso intensivo de dados históricos.
O modelo utiliza a seguinte fórmula para calcular o esforço:
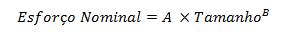
Figura 10 – Fórmula de cálculo do esforço do projeto (Boehm, 2005)
Segundo Boehm (2005), a constante A captura o efeito linear do tamanho do projeto no esforço necessário. B é um fator exponencial de ajuste de acordo com o tamanho do projeto. O Tamanho se refere à dimensão do projeto e seu valor pode ser medido em milhares de linhas de código, pontos de objeto ou pontos de função, geralmente derivado de outra técnica de estimativa.
O fator exponencial B é ajustado para cada projeto a partir de um conjunto de fatores definidos no modelo COCOMO II, os quais levam em consideração, por exemplo:
- se o projeto foi precedido por outro semelhante;
- se os riscos e a arquitetura são claramente definidos;
- o entrosamento da equipe;
- a maturidade do processo.
Além disso, o Esforço Nominal calculado pode ser ajustado por fatores relacionados ao produto, à plataforma, ao projeto e mesmo também pessoais. Por exemplo, o fator DATA permite o ajuste pelo tamanho do banco de dados, RELY considera a confiabilidade exigida do software, CPXL a complexidade do produto, ACAP a capacidade dos analistas, TOOL o uso de ferramentas de desenvolvimento e assim por diante.
Cada fator recebe uma classificação numa escala de cinco níveis (muito baixo, baixo, nominal, alto, muito alto). O ajuste é realizado multiplicando-se os fatores individuais pelo Esforço Nominal.
Clark (1998) define o COCOMO como um modelo paramétrico, ou seja, que utilizada uma representação matemática idealizada do mundo real baseada em parâmetros quantitativos ou qualitativos. Embora os parâmetros sejam derivados, em sua maioria, de julgamentos subjetivos, o modelo propõe que, através dos ajustes adequados, é possível obter uma estimativa com 70% de confiabilidade (Boehm, 2005).
PROBE
O PROBE (Proxy Based Estimating – Estimação Baseada em Proxy) é uma técnica de estimação indireta baseada em objetos e dados históricos (Humphrey, 2000, p.12).
Primeiramente, os engenheiros identificam os objetos necessários para a construção do produto de software e então determinam aproximadamente o tipo e o número de funções de cada objeto. Com base em dados históricos, compara-se cada objeto com objetos similares e estima-se o tamanho do mesmo em linhas de código usando regressão linear.
A estimação do esforço é realizada de forma similar. Com base nos dados históricos, aplica-se a regressão linear para estimar o esforço necessário para o desenvolvimento. Os dados devem mostrar uma relação direta entre o tamanho do programa e o tempo de desenvolvimento.
Para gerar o cronograma, cada engenheiro deve estabelecer em que ele irá trabalhar no projeto semanalmente ou diariamente, calculando-se assim o tempo necessário para conclusão de suas tarefas.
Durante o desenvolvimento, os engenheiros devem armazenar os dados de tempo e tamanho do projeto atual para planejamentos futuros.
Planning Poker
Alguns processos ágeis, como o Scrum, encaram o projeto de software como um jogo. Nessa linha, alguns autores consideram a melhor forma de estimar uma espécie de poker com as histórias de usuário do backlog (Cohn, 2006, p. 55).
No Planning Poker, todos os membros da equipe de desenvolvimento se reúnem. Primeiramente, cada membro recebe cartas. Cada carta contém um valor da escala de story point definida para o projeto. Para cada história de usuário, os membros escolhem secretamente a carta com o valor que consideram ser o tamanho daquela história. Então, todos mostram suas cartas ao mesmo tempo. Quando há consenso, a estimativa seria confiável. Se um ou mais valores forem discrepantes, os membros discutem entre si o motivo porque a história de usuário seria mais ou menos complexa. Após entrarem num consenso, uma nova rodada de cartas é realizada. Isso é feito até que todos estejam de acordo com a estimativa.
Os “agilistas” afirmam que esta técnica tem funcionado bem pelos seguintes motivos (Cohn, 2006, p. 59):
- aqueles que sabem como fazer o trabalho são os que fazem as estimativas;
- o diálogo faz com que os estimadores tenham que justificar suas estimativas, portanto eles pensam bem no que estão fazendo;
- a discussão em grupo, segundo alguns estudos, levam a melhores estimativas.
O Planning Poker geralmente é feito de forma mais intensa, porém menos detalhada, no início do projeto, de modo a gerar as estimativas iniciais necessárias para o planejamento geral e o número de iterações.
No início de cada iteração, sugere-se levar algo em torno de uma hora para detalhar as estimativas das histórias de usuário que serão implementadas, as quais, que nesse ponto, estão dividias em tarefas. O tempo de estimar varia de acordo com o tamanho da iteração.
Estimação por velocidade e aceleração
A velocidade de desenvolvimento é a quantidade de story point que uma equipe consegue implementar em um determinado intervalo de tempo (Cohn, 2006, p. 39). A velocidade pode ser calculada medindo-se o tempo que a equipe levou para concluir cada ponto de história.
A estimação das próximas histórias pode ser feita ou ajustada de acordo com a velocidade da equipe. Além disso, basta aplicar a velocidade às histórias de usuário restantes para obter-se a estimativa geral de conclusão do projeto.
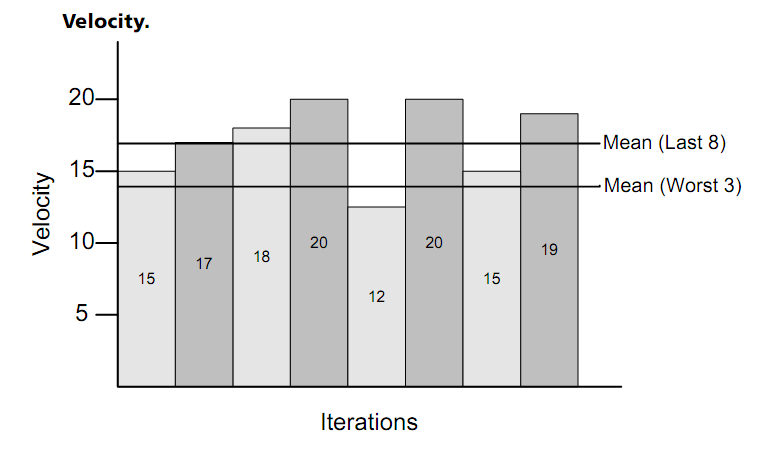
Figura 11 – Gráfico de Velocidade (Cohn, 2006, p. 237)
A Figura 11 contém um gráfico de velocidade por iteração. A velocidade média permite saber se o projeto está avançando de acordo com o esperado.
A aceleração do desenvolvimento pode ser calculada quando há uma tendência de aumento ou declínio da velocidade de desenvolvimento. Decisões gerenciais podem ser tomadas antecipadamente se os desenvolvedores estão terminando as histórias de usuário mais rapidamente ou mais lentamente a cada iteração.
Conclusão
O uso das técnicas e modelos de estimação depende do contexto. Alguns elementos são complementares, como a técnica de Pontos de Função e o modelo COCOMO, enquanto outros são incompatíveis, tal como o Planning Poker e técnicas semelhantes.
Embora não se possa afirmar definitivamente a superioridade absoluta de um modelo ou técnica, a utilização de um modelo ou técnica adequada pode guiar o estimador a melhores resultados, alavancando suas habilidades através de uma metodologia bem definida.
Por outro lado, qualquer estimador que se apoia em determinado modelo ou técnica como uma “bala de prata” sem compreender a natureza das estimativas, inevitavelmente irá se deparar com uma realidade muito diferente da esperada.
Entender o que são estimativas e no que consiste a tarefa de estimação é fundamental e mais importante do que adotar uma técnica ou modelo em específico.