Neste tutorial, vamos instalar o Ubuntu, uma das distribuições linux mais populares da atualidade, numa máquina virtual.
Você poderá usar isso para várias finalidades. Aqui no blog, em breve, usaremos em artigos sobre Hadoop e Big Data.
Virtualização
Para quem não está acostumado com virtualização, uma máquina virtual (Virtual Machine, em Inglês) é um ambiente que simula um computador, com sistema operacional próprio, mas que você pode executar dentro do seu sistema atual.
Isso significa que você pode executar um sistema operacional linux dentro do seu Windows e vice-versa. Eu mesmo uso primariamente o Windows 7, mas tenho imagens com XP e diversas distribuições linux.
O sistema operacional principal da máquina é chamado de hospedeiro (host). Os sistemas operacionais usados dentro de máquinas virtuais no sistema hospedeiro são chamadas de sistemas convidados (guests).
Essa técnica tornou-se viável num passado não tão distante quando o hardware atingiu um bom nível de eficiência, inclusive hoje com tecnologia que torna a virtualização quase tão eficiente como um sistema tradicional.
A virtualização traz vários benefícios. O principal é possibilitar a criação da tão famigerada computação em nuvem (cloud computing). Além disso, as empresas que dependem de infraestrutura de TI tanto para desenvolvimento quanto para produção podem usufruir de maior facilidade para a criação de novos ambientes e servidores virtuais, além de flexibilidade para o gerenciamento. Desenvolvedores ou mesmo usuários domésticos como eu podem ter vários servidores com diferentes tecnologias em seu notebook pessoal, inicializados apenas de acordo com a demanda.
Existem ainda sites que disponibilizam ambientes com diversas tecnologias prontos para os administradores usarem em servidores. Um deles é o TurnKey Linux. Baixando imagens de discos virtuais relativamente pequenas, você tem um sistema pronto para uso e somente com o que é necessário para executar a tecnologia escolhida. Enfim, você pode ter um servidor pronto em uma máquina virtual em apenas alguns minutos.
VirtualBox ou VMWare Player?
Os programas gratuitos de virtualização para usuários domésticos mais conhecidos são o VirtualBox da Oracle e o VMWare Player. Ambos são bons produtos, maduros e em constante evolução. Mas com funcionalidades específicas um pouco diferentes, além de vantagens e desvantagens.
Como sou usuário de ambos posso dizer que na prática não há um ganhador absoluto. Depende do uso que fizermos deles. O VMWare, por exemplo, permite copiar e copiar um arquivo do sistema hospedeiro para o convidado e vice-versa. O VirtualBox, por sua vez, traz várias funcionalidades que o VMWare só disponibiliza na versão paga.
Para quem faz questão de uma solução mais completa e possui condições de arcar com as despesas, o melhor seria adquirir uma versão paga do VMWare. Já o usuário doméstico que está começando se dará muito bem com qualquer versão gratuita.
Aqui usaremos o VirtualBox. Mas se alguém optar pelo concorrente não encontrará tanta dificuldade em atingir o mesmo objetivo.
Funcionalidades interessantes do VirtualBox
Existem algumas funcionalidades bem legais quando usamos uma máquina virtual. Irei descrever algumas nas próximas linhas que estão disponíveis no VirtualBox.
Por exemplo, você pode pausar uma máquina virtual a qualquer momento através do menu Máquina > Pausar.
Também é possível salvar snapshots da máquina através do menu Máquina > Criar Snapshot. Sabe o que significa isso? Ao criar um snapshot, você tira uma “fotografia” ou “instantâneo” do sistema naquele momento. Então pode “pintar e bordar”, realizar testes, instalação de programas ou até vírus. Quando cansar da brincadeira, basta restaurar o snapshot e o sistema (disco e memória) voltarão ao estado salvo como se nada tivesse acontecido.
Caso em algum momento você deixe a máquina virtual em tela cheia ou o cursor do mouse seja capturado por ela de forma que você não consiga sair, não se desespere. A tela usada para liberar o mouse e também para algumas teclas de atalho é o CTRL da direita do seu teclado. Este é o padrão e você pode mudá-lo. Essa tecla especial é chamada tecla do hospedeiro, isto é, que permite acessar comandos no sistema hospedeiro. Por exemplo, CTRL+F alterna a máquina virtual entre modo de tela cheia e janela.
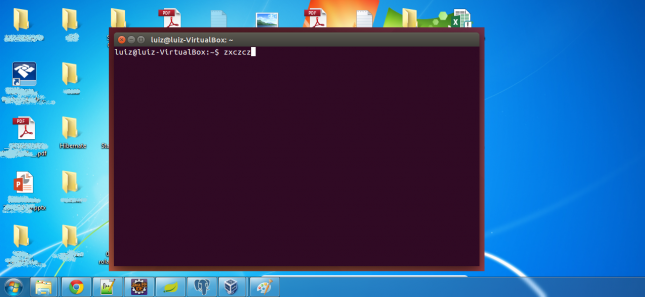
Outra funcionalidade interessante, embora deva ser usada com cuidado, é o modo Seamless. Com ele, os programas abertos no sistema dentro da máquina virtual “misturam-se” com a área de trabalho do sistema hospedeiro, dando a impressão de haver apenas um sistema operacional. Veja o seguinte exemplo de um terminal aberto no Ubuntu e exibido em seamless mode:
Configuração de Hardware
Máquinas mais novas, como o Intel i7, possuem suporte em nível de hardware para virtualização. Entretanto, até algum tempo atrás essas capacidades eram desativadas por padrão. Isso chegava a impedir a virtualização de sistemas operacionais convidados de 64 bits.
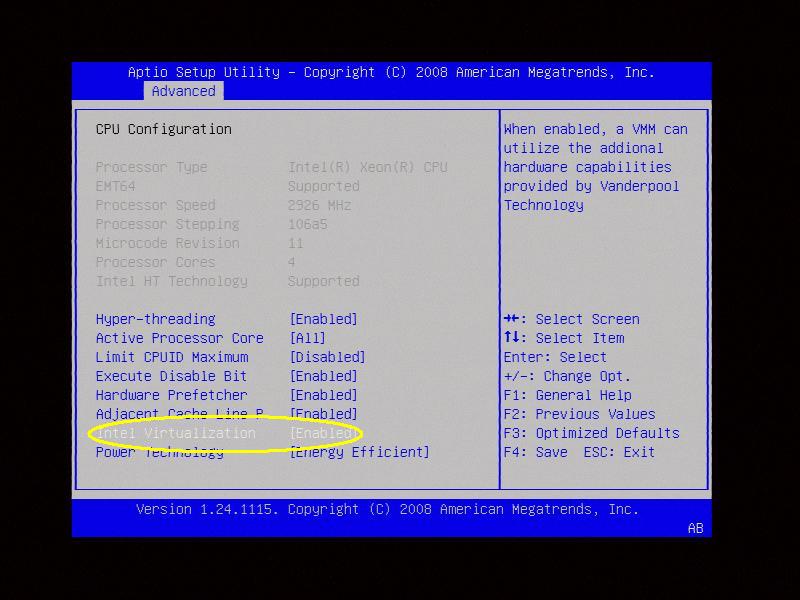
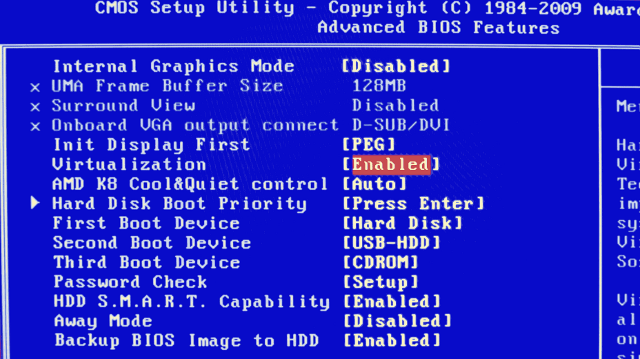
Leia o manual da sua placa mãe e do seu processador e verifique se eles possuem suporte nativo para virtualização. Procure por algo como VT-x (Intel) ou AMD-V. Veja um exemplo da BIOS para um processador AMD:
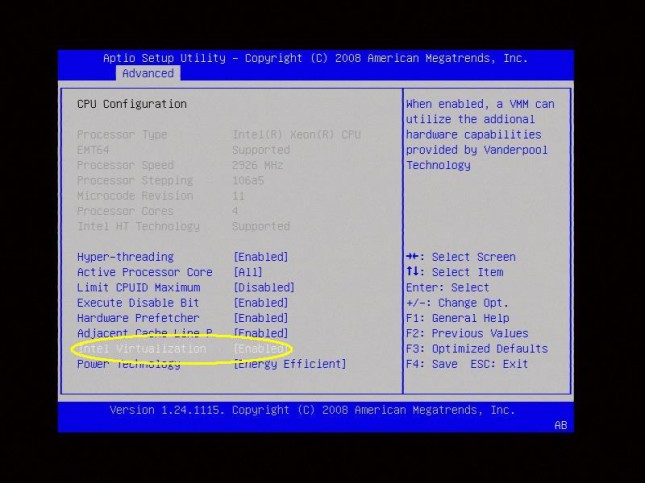
E aqui outro exemplo para um processador Intel:
Lembre-se, sem o suporte nativo, você não será capaz de instalar um sistema operacional de 64 bits como convidado no VirtualBox. Entretanto, se não estou enganado, o VMWare consegue emular via software a virtualização de sistemas 64 bits, mas de qualquer forma o desempenho será sofrível.
Instalando o VirtualBox e as extensões
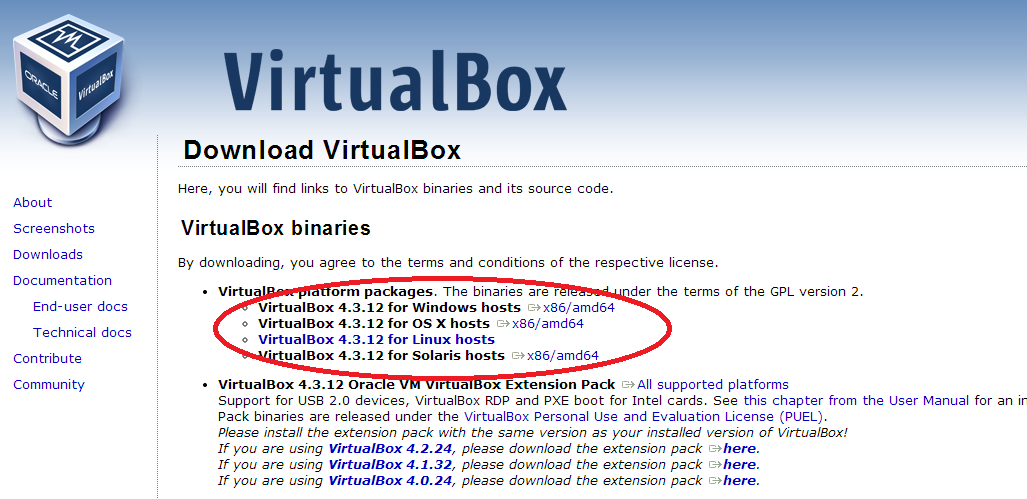
Acesse a página de downloads e baixe a versão correspondente ao seu sistema operacional.
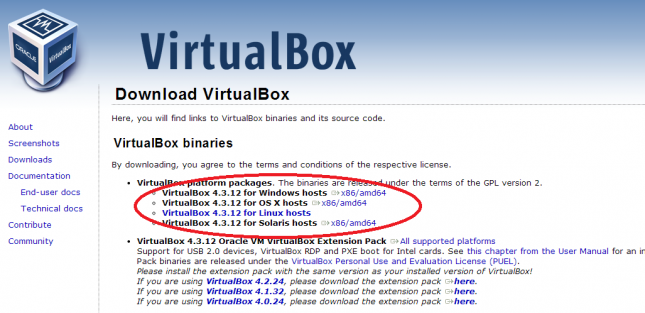
Baixe também as extensões para o sistema convidado.
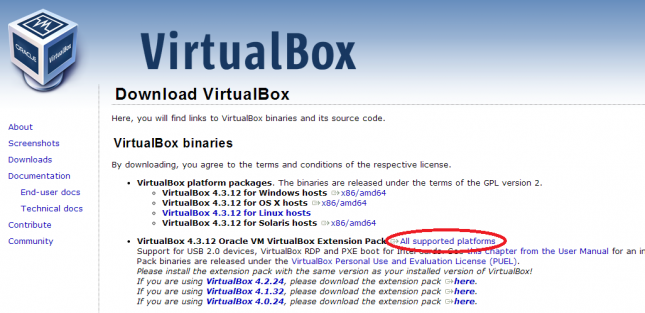
As extensões trarão várias facilidades, tais como: redimensionamento automático da tela, melhor integração do mouse, compartilhamento de pastas automático entre o sistema hospedeiro e o convidado, uso da USB dentro da máquina virtual e muito mais.
Execute o primeiro arquivo baixado para instalar o VirtualBox. Em geral você não precisa alterar nenhuma configuração, então simplesmente avance até o final da instalação
Confirme ainda a instalação de todos os drivers, que serão usados para integrar seus dispositivos como mouse, teclado e rede com a máquina virtual.
Após concluir, execute também o outro arquivo para instalar as extensões do convidado (Guest Additions). O nome deve ser algo como Oracle_VM_VirtualBox_Extension_Pack-4.3.12-93733.vbox-extpack. O programa VirtualBox será aberto. Aceite o contrato para concluir a instalação.
Dando tudo certo, não se esqueça que o atalho adicionado no Menu Iniciar é “Oracle Virtual Box”.
Criando uma máquina virtual
Na tela principal do VirtualBox, clique no botão Novo.
Na tela de criação, digite “Ubuntu 14”. Note que os demais campos serão preenchidos automaticamente.
Clique em Próximo e selecione a quantidade de memória para seu novo ambiente. Aqui vou deixar com 2 Gigabytes (2048 Megabytes), mas uma dica é não ultrapassar 50% da memória total do seu computador.
Clique em Próximo. Nesta tela, você poderá criar um novo disco rígido virtual. Um HD virtual é simplesmente um arquivo grande que ficará no seu sistema de arquivos, o qual funcionará como se fosse um HD para o sistema da máquina virtual. A não ser que tenha outros planos, deixe marcada a opção para criar um disco novo.
Clique em Criar. Na próxima tela, você poderá escolher o formato do arquivo desse novo disco. Vamos deixar o formato nativo do VirtualBox, o VDI.
Clique em Próximo. Nesta tela você pode escolher entre duas opções:
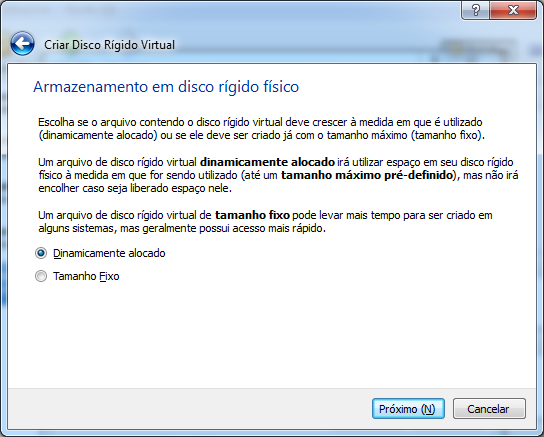
- Dinamicamente alocado: nesta opção, o arquivo do disco virtual vai aumentando de tamanho somente quando novos arquivos forem gravados. Isso significa que se você criar um disco de 30 Gigabytes, mas a instalação do SO e os demais arquivos ocuparem apenas 2 Gigabytes, então o arquivo terá apenas 2 Gigabytes. O disco vai aumentando de tamanho na medida do uso até alcançar o limite de 30 Gigabytes.
- Tamanho fixo: nesta opção, um disco virtual de 30 Gigabytes vai ocupar todo esse tamanho no seu disco verdadeiro.
Já que economizar espaço nunca é demais, vamos deixar a primeira opção selecionada.
Clique em Próximo. Agora vamos selecionar o nome do arquivo e o tamanho do disco virtual.
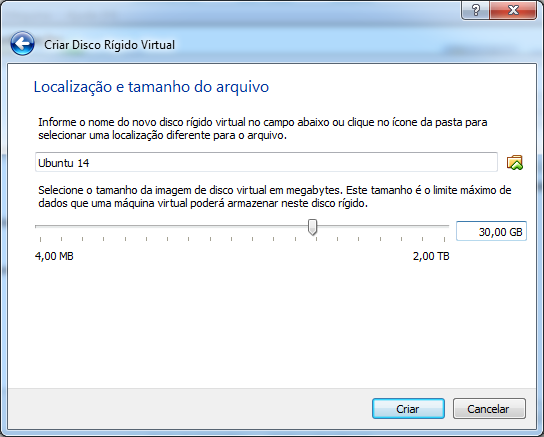
Caso tenha mais de uma partição ou HD no seu computador, você pode mudar o local do arquivo do disco virtual. Em algumas situações já criei máquinas virtuais no meu HD externo. Porém, para este tutorial, vamos apenas deixar tudo como está, pois o padrão é suficiente.
Finalmente, clique em Criar.
Agora você tem um computador virtual para brincar!
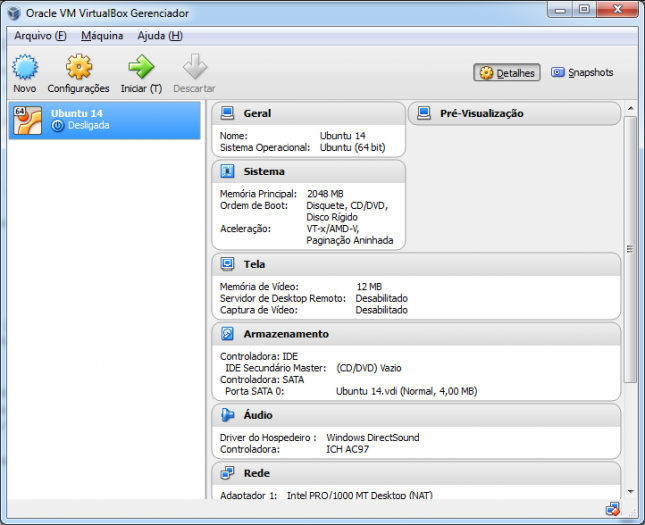
Instalando o Ubuntu
Antes de mais nada, acesse a página de downloads da versão desktop do Ubuntu e baixe a versão adequada para o seu computador. Neste tutorial, fiz o download da versão 64 bits, cujo nome do arquivo baixado é ubuntu-14.04-desktop-amd64.iso e possui 964 Megabytes.
Com a imagem do disco de instalação do nosso novo sistema operacional, podemos então iniciar a máquina virtual e a instalação.
Na tela principal, selecione a VM (máquina virtual) criada e clique em Iniciar.
Antes da inicialização da VM, o VirtualBox vai saudá-lo com uma tela solicitando o disco de boot. Isso ocorre porque ele verificou que o disco virtual está vazio.
Clique no botão à direita do campo e selecione o arquivo do Ubuntu anteriormente baixado.
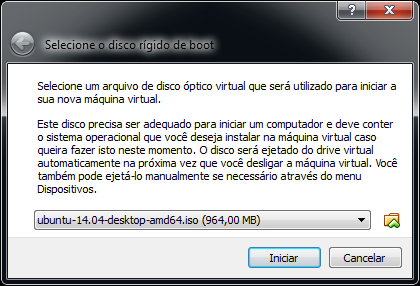
Clique em Iniciar e aguarde a inicialização da instalação do Ubuntu.
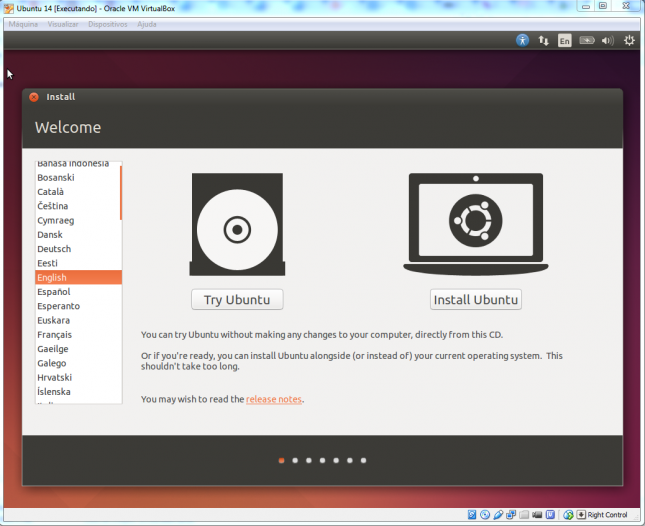
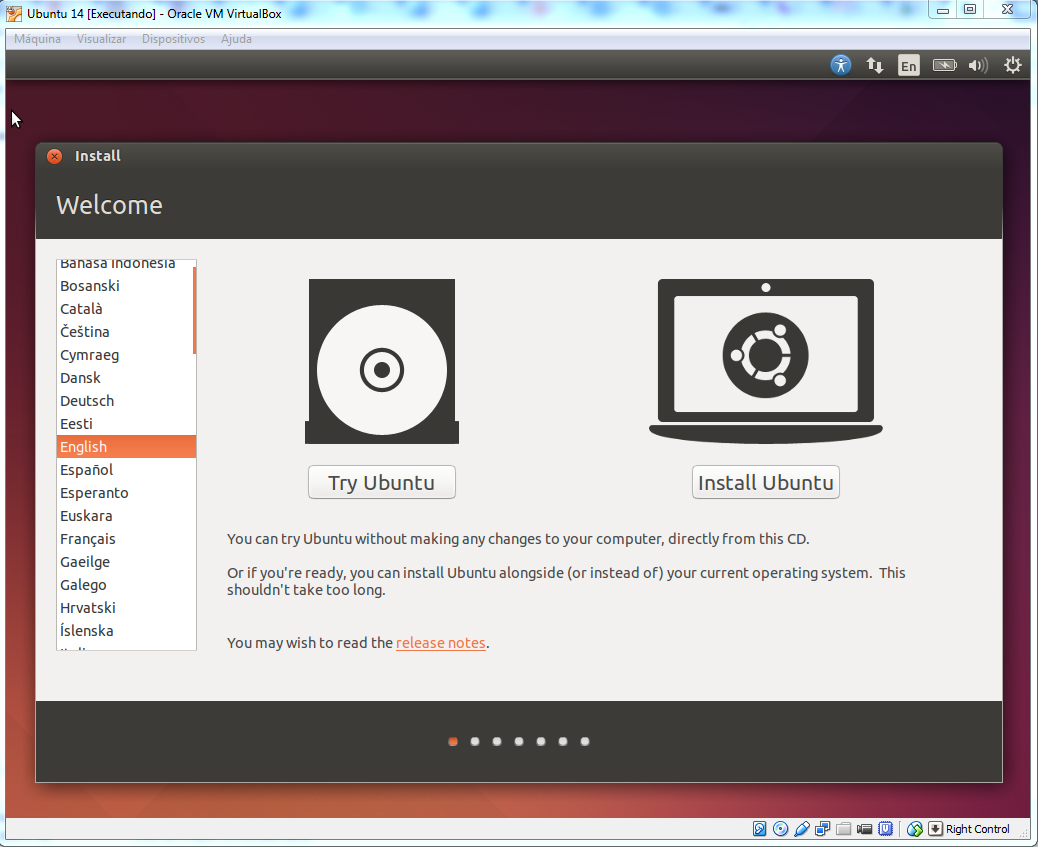
Você pode selecionar sua língua materna ou deixar em Inglês. Eu prefiro o Inglês porque em TI as traduções acabam por confundir mais que ajudar. Clique em Install Ubuntu ou Instalar Ubuntu, dependendo da sua escolha.
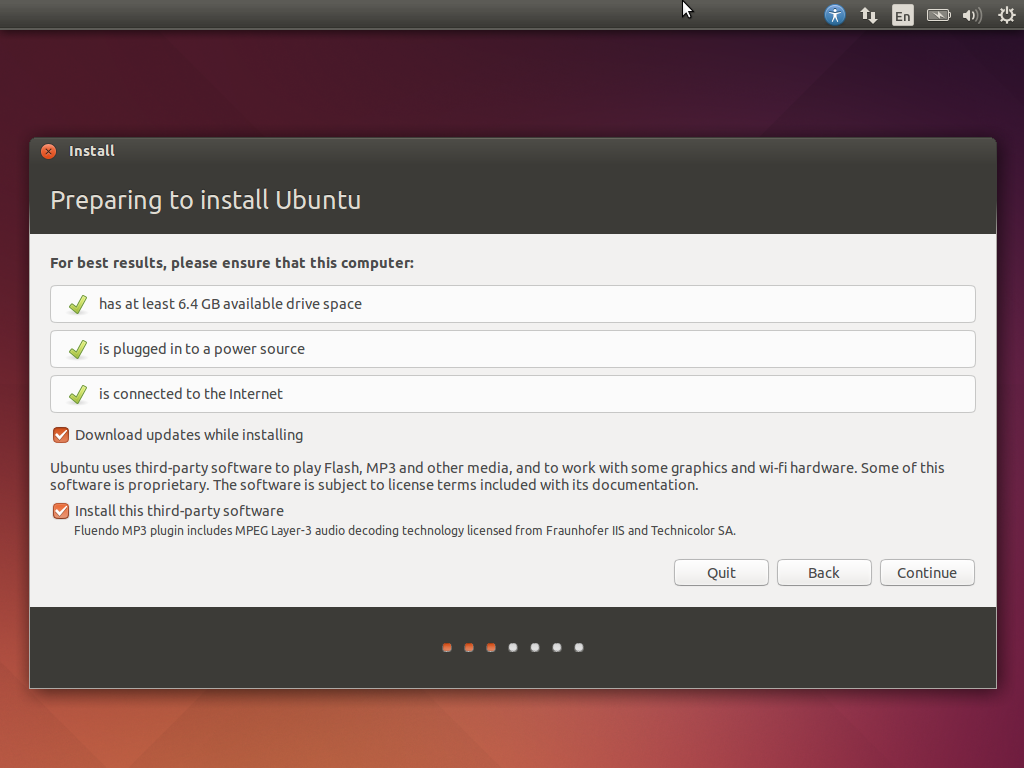
A próxima tela irá informar se o Ubuntu vai executar bem na máquina onde está sendo instalada. Além disso, há opções para já instalar as últimas atualizações e alguns softwares de terceiros. Selecione todas as opções e clique em Continue.
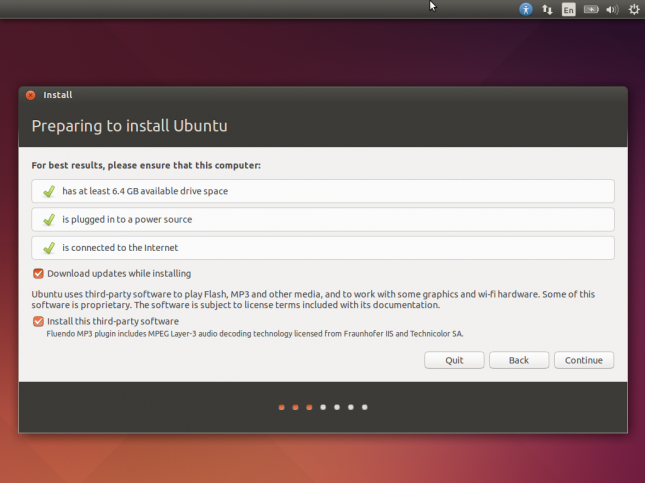
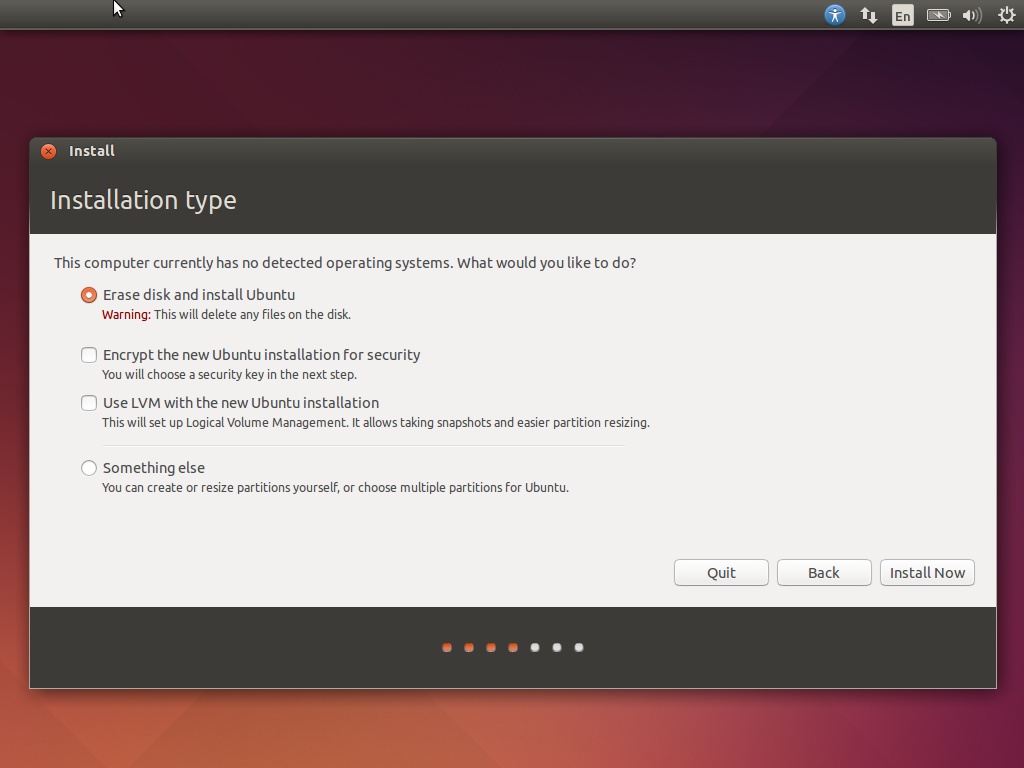
Agora há opções para formatar ou particionar o disco antes da instalação. Como temos um disco virtual dedicado, simplesmente selecione a primeira opção para formatá-lo e executar uma instalação limpa.
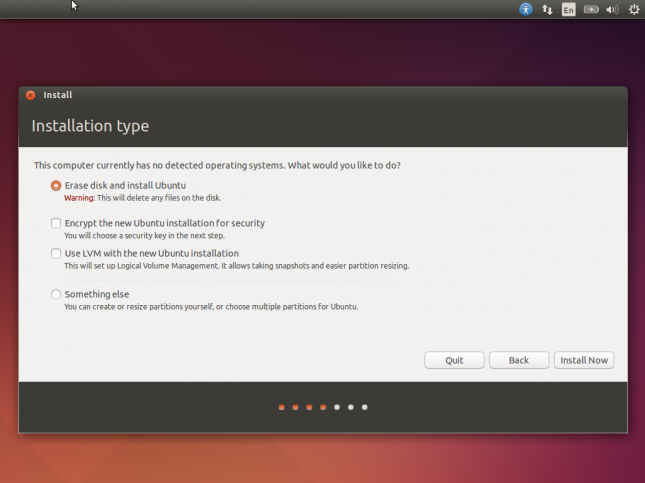
Clique em Install Now.
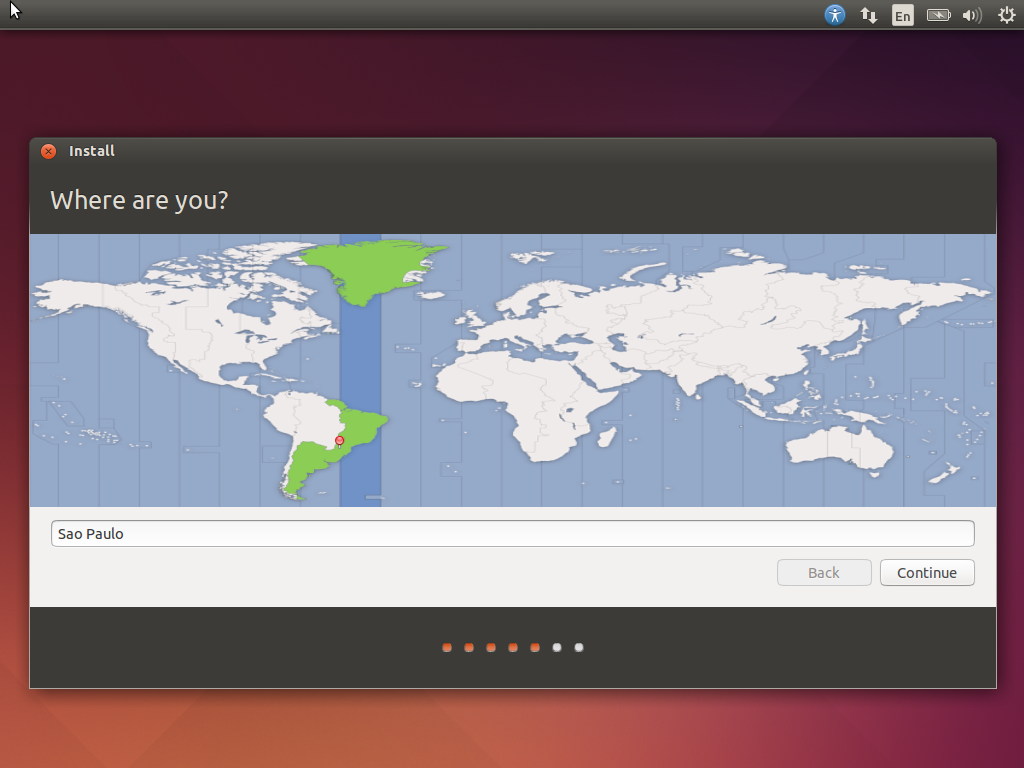
Na verdade, a instalação não vai começar ainda. Isso deve ter sido uma grande falha de design. A próxima tela contém a seleção da sua localidade. Digite o nome da capital do seu estado. Coloquei “Sao Paulo”.
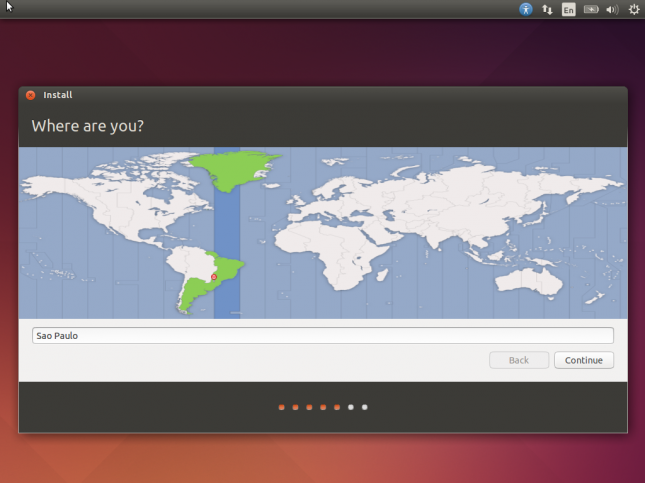
Clique em Continue.
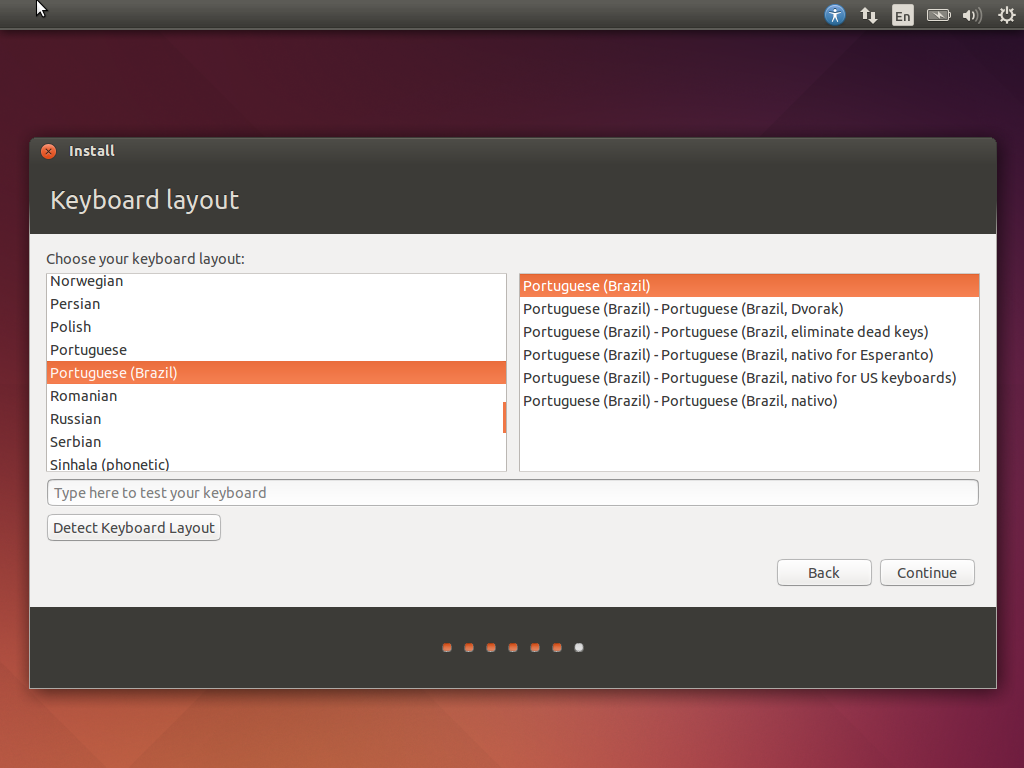
Na próxima tela você pode selecionar o tipo do seu teclado. Teste-o para ver se está ok e clique novamente em Continue.
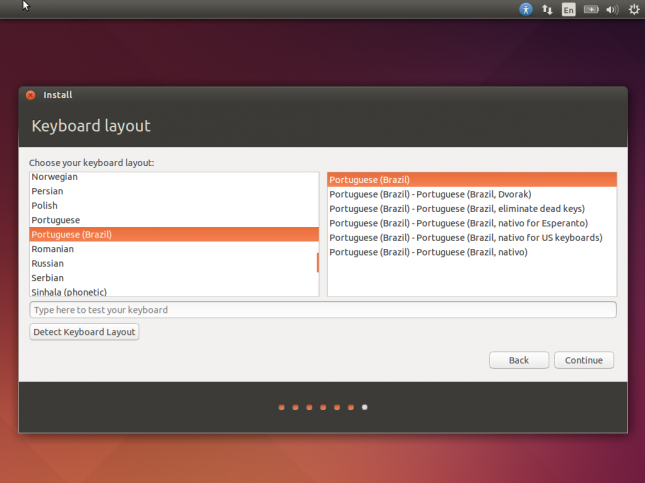
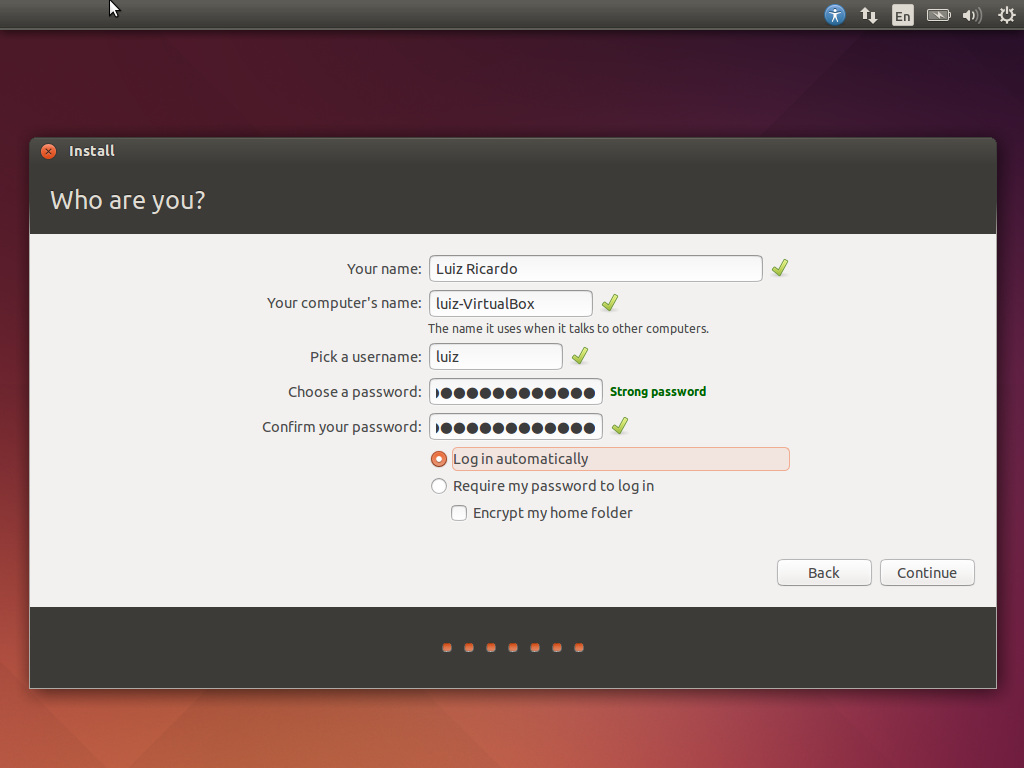
Finalmente, digite seus dados de usuário, incluindo a senha, e clique em Continue para iniciar a instalação de verdade.
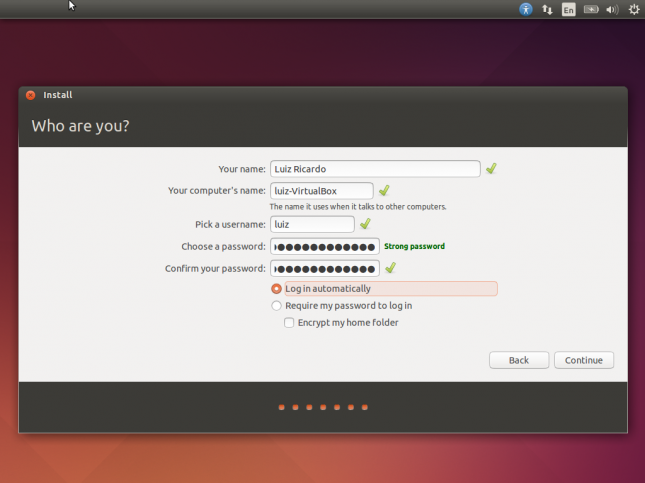
Aguarde o processo de instalação.
Ao final, uma caixa de diálogo vai aparecer informando que o sistema deve ser reiniciado. Clique em Restart Now.
Nota 1: enquanto fazia este tutorial, o Ubuntu travou e não reiniciou corretamente. Então, fui até o menu Máquina > Reinicializar para forçar um reset.
Nota 2: a instalação do Ubuntu ejetou automaticamente o disco de instalação virtual do Ubuntu. Se estiver instalando outro sistema operacional que não faça isso, use o menu Dispositivos > Dispositivos de CD/DVD > Remover disco do drive virtual para não iniciar a instalação do sistema novamente por engano.
Pronto, o sistema está instalado e pronto para uso.
Melhorando a integração entre sistema hospedeiro e convidado
Note que a janela do ubuntu ficou bem pequena, quase inutilizável. Vamos resolver isso!
Lembra que instalamos as “extensões do convidado” (Guest Additions) no VirtualBox? Elas facilitarão o uso da máquina virtual de várias formas, mas falta a parte da instalação no sistema convidado. Isso ocorre para que o VirtualBox consiga “conversar” com o SO que está na máquina virtual.
Para fazer isso, devemos seguir as instruções da documentação do VirtualBox que nos dá alguns comandos.
Vamos abrir o terminal de comandos clicando no primeiro botão à esquerda (equivalente ao “Iniciar” do Windows) e pesquisando na caixa de busca por “terminal”.
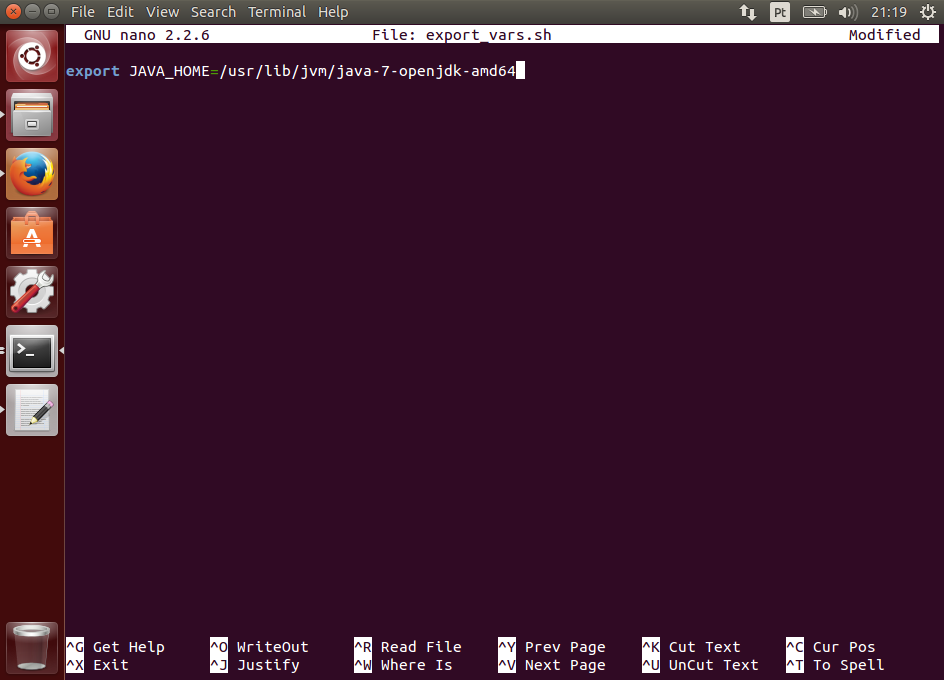
Se nada mudou no VirtualBox ou no linux desde que escrevi este tutorial, as instruções do Guest Additions para o Ubuntu consistem nos seguintes comandos:
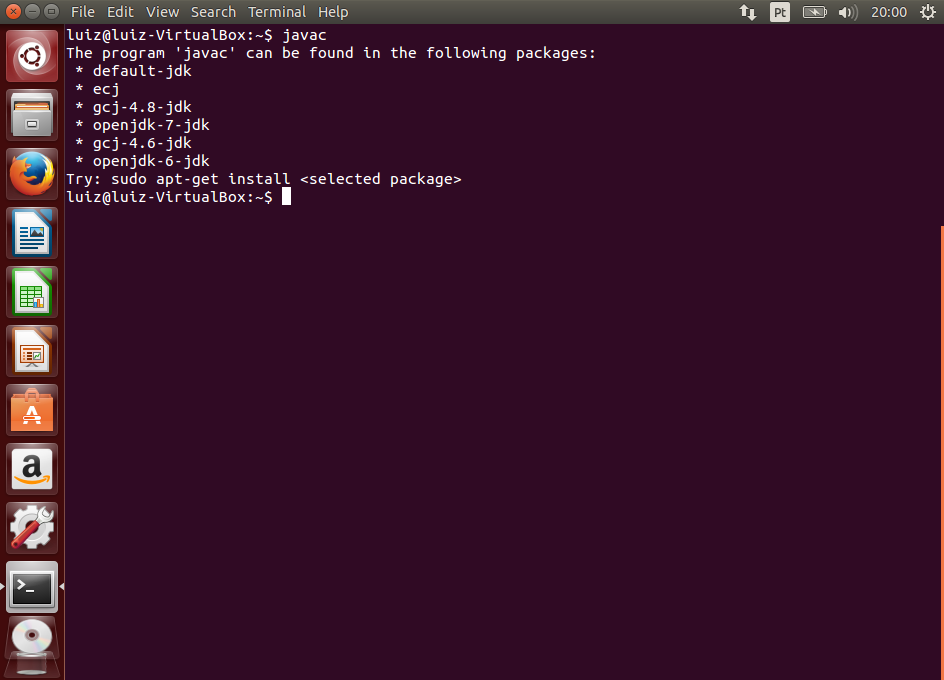
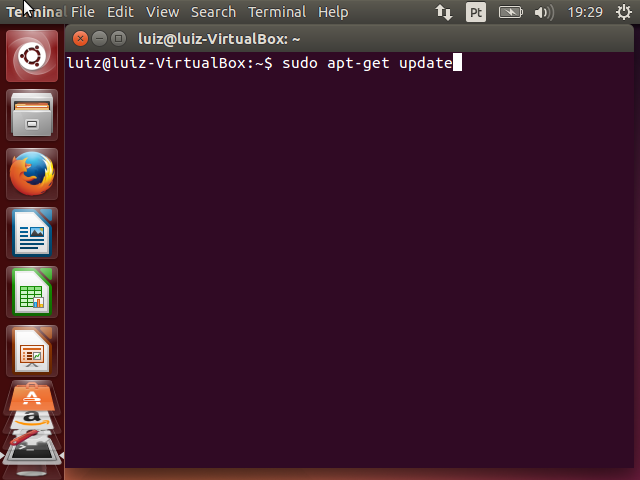
sudo apt-get update
sudo apt-get upgrade
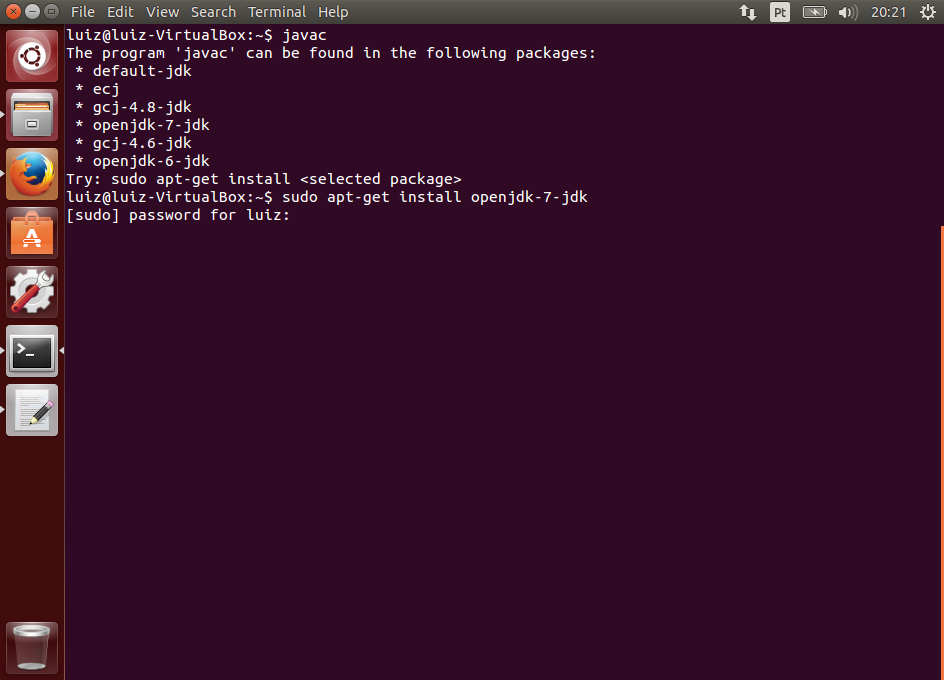
sudo apt-get install dkms
Nota: um usuário comentou que não conseguiu executar o último comando com sucesso, tendo substituído por sudo apt-get install virtualbox-guest-dkms. Isso pode ser necessário se estiverem sendo usadas diferentes configurações ou outras versões do Ubuntu ou ainda outras distribuições linux.
O comando sudo que prefixa os demais não está na documentação, mas é necessário se você não está executando o terminal com privilégios de superusuário (administrador).
O primeiro comando é apt-get update. Ele irá atualizar o índice de pacotes do Ubuntu. Dessa forma ele saberá as últimas versões de todos os seus componentes e programas. Após digitar o comando, o sistema irá solicitar a senha do usuário e então executar a ação.
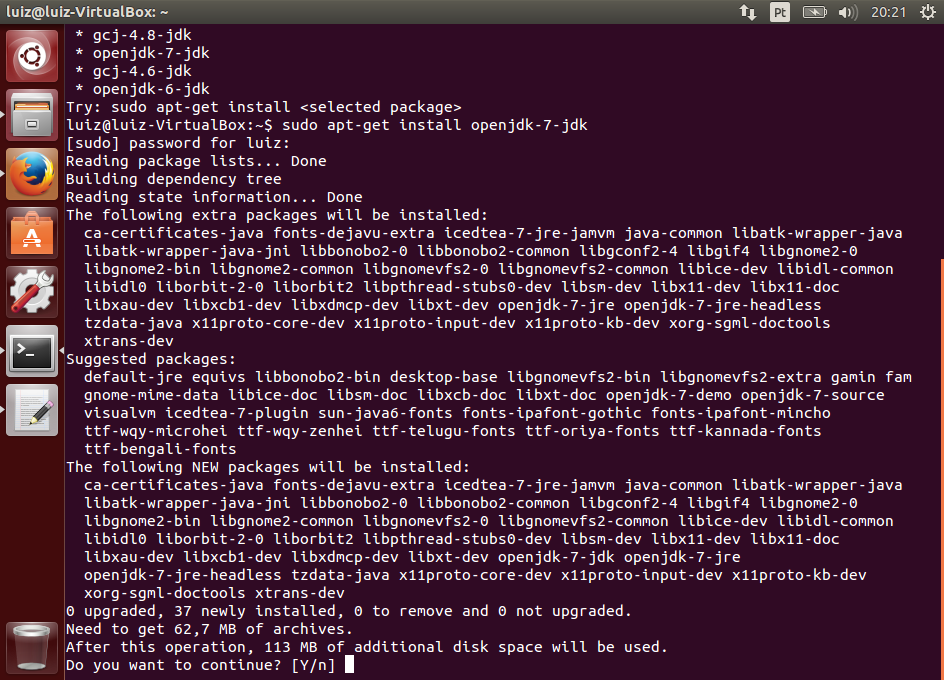
O próximo comando é apt-get upgrade. Ele vai efetivamente instalar todas as atualizações do sistema. Após entrar o comando, o Ubuntu vai solicitar algumas confirmações. Pressione Y (yes) para confirmar a atualização e aguarde.
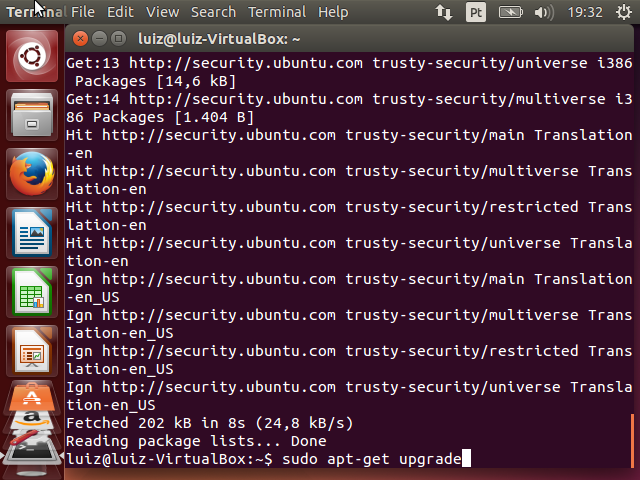
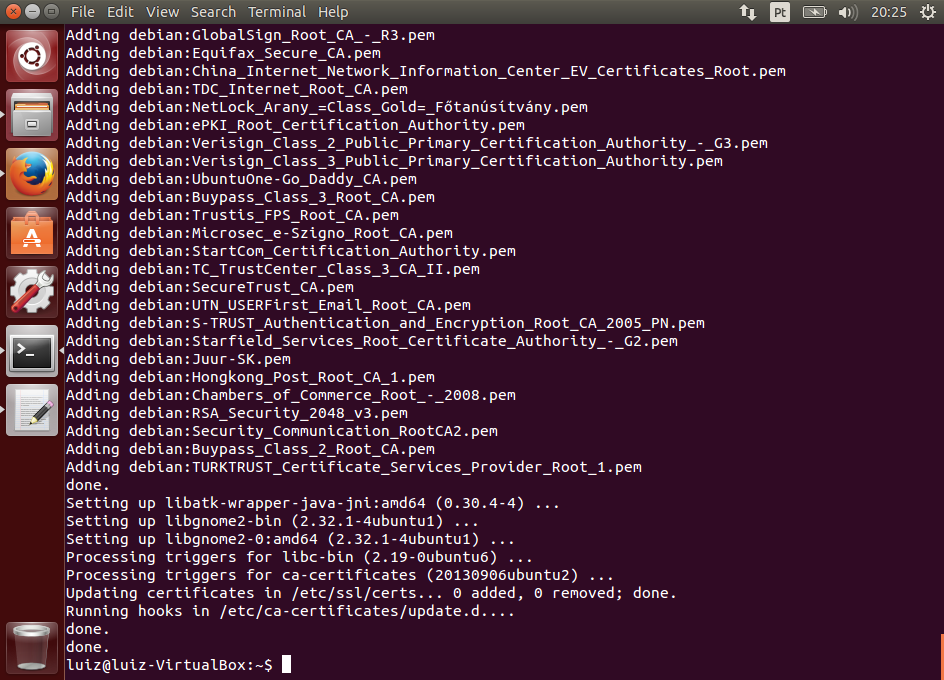
Após a atualização do sistema, executaremos o último comando: apt-get install dkms. Este comando vai instalar o pacote dkms, que possibilita a módulos do kernel serem atualizados independentemente. O Guest Additions precisa disso porque ele é um módulo do Kernel e é atualizado com frequência, caso contrário seria necessário recompilar o Kernel do linux a cada atualização.
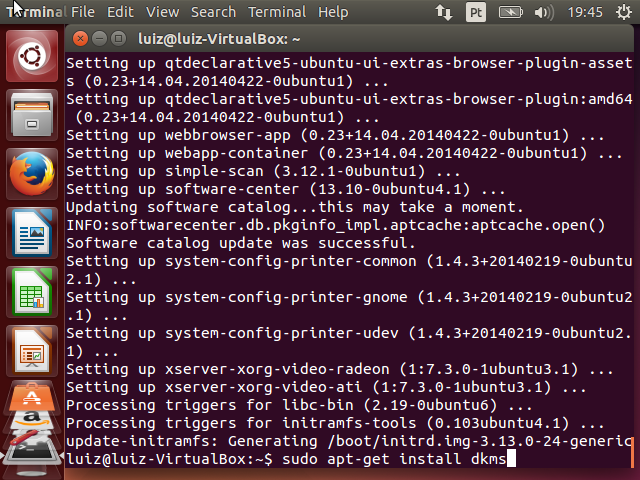
O comando vai pedir a confirmação da instalação. Pressione Y quando necessário.
Neste momento já cumprimos todos os pré-requisitos para a instalação do Guest Additions. Então vamos à instalação em si.
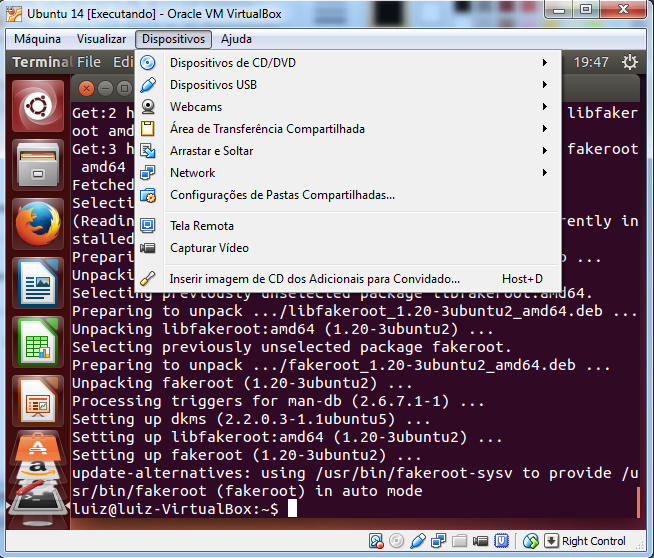
Acesse o menu Dispositivos > Inserir imagem de CD dos Adicionais para Convidado....
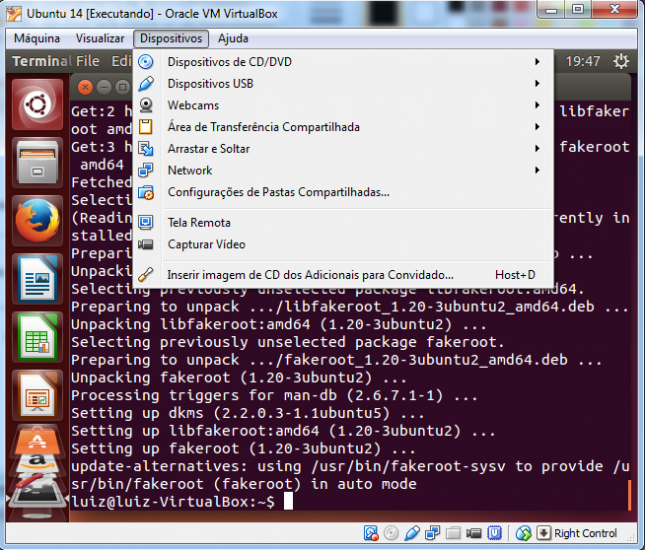
Ao acionar o menu, uma imagem de CD do VirtualBox será montada no sistema do Ubuntu e a execução automática (auto run) ocorrerá. Uma mensagem de confirmação será exibida.
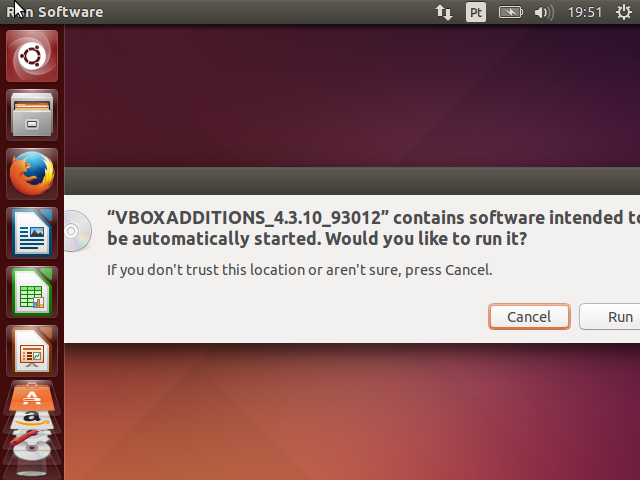
Clique em Run. A senha será novamente solicitada. Digite-a e aguarde o final da instalação.
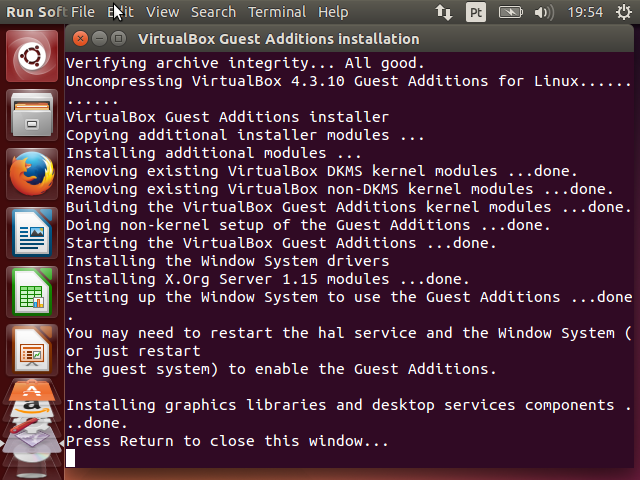
Finalmente, vamos reiniciar o sistema para ativar o módulo que acabamos de instalar. Clique no botão do sistema no canto superior direito do Ubuntu e selecione a opção Shut Down....
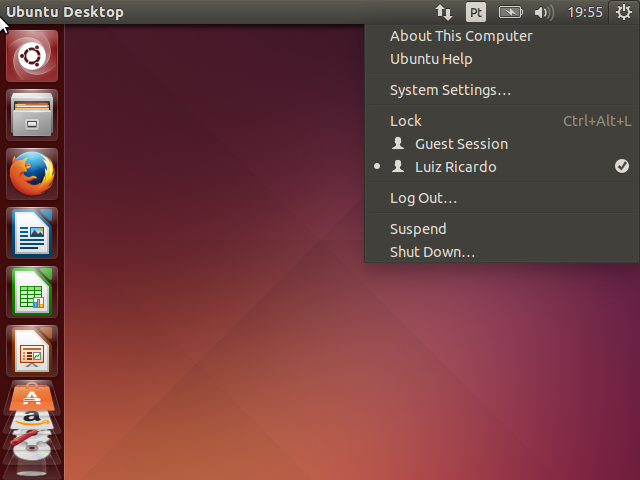
Na tela que vai abrir, clique no botão da esquerda para reiniciar.
Após a reinicialização, você poderá, entre outras coisas, redimensionar a janela do VirtualBox como quiser e o Ubuntu irá se ajustar a esse tamanho. Legal, né? Esta é a opção Visualizar > Redimensionar Tela Automaticamente que estava desabilitada anteriormente, mas agora veio ativada por padrão.
Palavras finais
Virtualização é um conceito importantíssimo no mundo de hoje. Desenvolvedores de software não precisam ser especialistas em virtualização, mas devem ter bons conceitos sobre como isso funciona e devem saber usar todos os benefícios a seu favor.
Criar máquinas virtuais não é difícil, basta ter uma base sobre o assunto e saber usar as ferramenta já existentes, que estão cada vez mais intuitivas e poderosas.
Os benefícios da criação de máquinas virtuais são inúmeros, a começar por podermos usufruir de uma variedade de ambientes dentro de um único computador.
Em futuros artigos, pretendo trazer tutoriais envolvendo Hadoop, inclusive com a criação de um cluster, cada um em uma máquina virtual, para processamento Big Data.