Este artigo é o Capítulo III da minha monografia de Especialização em Engenharia de Software. Embora seja um referencial teórico e não acrescente nada de novo, espero que o possa ser útil de alguma forma para o leitor.
Introdução
Um sistema de software é construído através de um processo de desenvolvimento, seja ele formal ou empírico. Diversos modelos de processos surgiram ao longo do tempo, dentro os quais os principais são apresentados neste capítulo.
Ao adotar processos formais e reconhecidos aproveita-se o conhecimento e a experiência dos especialistas que os criaram. Isso inclui boas práticas, listas de verificação, atividades pré-definidas, entre outros. Existe o risco de usar indevidamente o processo, executando todas as atividades propostas sem a devida reflexão, desperdiçando tempo com o que não é importante e gerando uma falsa segurança baseada apenas no fato de se usar um processo conhecido.
Por outro lado, um processo empírico depende da experiência, habilidade e conhecimento da equipe. Profissionais experientes e maduros obtêm vantagens com a liberdade desse tipo de processo porque eles já adotam boas práticas de desenvolvimento, sabem quais atividades são necessárias para completar suas tarefas e sabem como prevenir e resolver problemas.
Existem também processos de gerência utilizados durante o desenvolvimento de software. Alguns foram criados especificamente para projeto de software e outros adaptados de modelos de gerência de projetos. Alguns modelos de desenvolvimento incluem elementos de gerenciamento e vice-versa. Em decorrência disso, podem existir lacunas num projeto que executa um processo incompleto Algumas organizações adotam processos complementares, de forma a preencher essas lacunas.
Definição de modelo de processo e processo de software
Um modelo de processo é uma abstração de um processo (Sommerville, 2003, p. 36). Esses modelos representam as abordagens utilizadas no desenvolvimento de software dentro das organizações. Com base nesses modelos, diversos processos foram propostos para o desenvolvimento de software com a finalidade de se construir um produto melhor, de menor custo e mais rapidamente.
Um processo de desenvolvimento de software consiste num conjunto de atividades e resultados associados que geram um software (Sommerville, 2003, p. 7). Em geral, os processos de desenvolvimento têm como foco os aspectos técnicos, como especificação, desenvolvimento, validação e evolução do software e devem prover transparência e flexibilidade para facilitar o gerenciamento do projeto.
O processo adotado por uma organização também é uma abstração em relação ao processo executado num determinado projeto. Em geral, o processo da organização é adaptado de acordo com as necessidades específicas do projeto.
Importância do gerenciamento de projetos
Existe a necessidade de gerenciar o processo de desenvolvimento de software através de modelos, processos, atividades e ferramentas específicos. O desenvolvimento de um software ganha sentido no contexto de um negócio e de uma organização. É importante alinhar os requisitos de negócio com o produto de software e gerenciar as atividades de desenvolvimento, verificando prazo, custo e qualidade para que o projeto não termine em fracasso do ponto de vista do negócio (Sommerville, 2003, p. 60).
Os processos de desenvolvimento podem incluir atividades de gerenciamento, tal como o Processo Unificado (Rational, 2001), mas existem modelos e processos específicos para gerenciamento de projetos. É possível adotar uma combinação de processos complementares de acordo com as necessidades do projeto e da organização.
A estimação de software é importante para o gerenciamento de um projeto. Decisões como o cancelamento de um projeto podem ser tomadas com base em estimativas de custo e prazo necessários para desenvolver um determinado sistema de software. Estimativas adequadas resultam em decisões gerenciais acertadas, enquanto estimativas irreais causam prejuízo.
Além disso, dados do esforço real comparado com o esforço estimado fornecem uma importante ferramenta para ajuste das estimativas do projeto corrente e nos projetos futuros. A experiência e os dados agregados através desta comparação permitem estimar as atividades futuras com maior acurácia e atuar mitigando riscos de descumprimento de prazos acordados. Para isso, o gerente deve possuir os registros organizados das atividades concluídas.
Classificação dos modelos em relação à burocracia e à iteratividade
A estimação deve considerar o quanto o processo onera as atividades de desenvolvimento. Quanto mais atividades extras, documentação e rigor forem exigidos, maior será o fator de ajuste necessário para as estimativas.
Este estudo considera modelos mais burocráticos e com maior rigor como modelos tradicionais. Modelos com pouca burocracia, também chamados de empíricos, incluem os modelos de processos ágeis.
Kroll (2006) classifica alguns modelos num gráficos cujo eixo horizontal é o grau de disciplina adotado e o eixo vertical o nível de iteratividade. Na Figura 2, o autor posiciona o modelo de maturidade de processo CMM com grau elevado de burocracia e baixa iteratividade, enquanto os modelos ágeis com pouca burocracia e alta iteratividade. O CMMI, uma evolução do CMM, é mais iterativo e menos burocrático. Já os processos ágeis são bastante iterativos e muito pouco burocráticos.
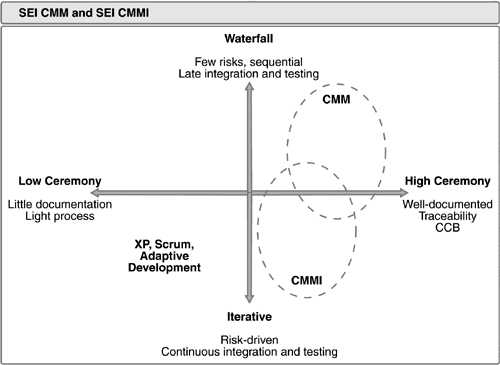
]1 Figura 2 – Grau de burocracia de processos tradicionais (Kroll, 2006, p. 36).
A Figura 3 apresenta a mesma ideia, incluindo agora o Processo Unificado. Devido a suas características de adaptação, o Processo Unificado abrange uma grande faixa do gráfico. Dependendo do projeto, ele pode ser adaptado para ser mais ou menos iterativo e disciplinado.
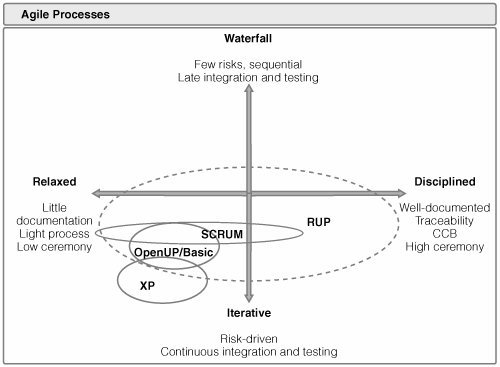
]2 Figura 3 – Grau de burocracia dos processos ágeis (Kroll, 2006, p. 45).
Modelos de desenvolvimento e gerenciamento de software
Os modelos de desenvolvimento de software são abstrações das abordagens de desenvolvimento utilizadas nas organizações. Eles podem ser aplicados em diferentes processos individualmente, combinados e com variações.
Os modelos afetam diretamente a forma como o projeto é gerenciado. Os modelos iterativos, por exemplo, definem que haverá atividades de planejamento em cada iteração ao longo do desenvolvimento.
A compreensão dos princípios, benefícios e desvantagens desses modelos auxilia no desenvolvimento e na estimação de um software ao fornecer uma visão geral da abordagem utilizada no projeto.
Modelos incrementais
Os modelos incrementais englobam os modelos de desenvolvimento cuja constituição é de pequenos ciclos de desenvolvimento realizados de forma iterativa, ou seja, a cada ciclo novos incrementos são adicionados no software (Pressman, 2006, p. 40), que ganha funcionalidades no decorrer do projeto. Em cada iteração é produzida uma versão parcial funcional do software.
Este modelo possui vantagens em relação a um modelo sequencial de desenvolvimento. Os incrementos podem ser planejados para gerir os riscos técnicos, uma boa prática adotada por processos modernos (Campos, 2009). Ele também absorve melhor as mudanças nos requisitos, principalmente quando alguns deles ainda não foram claramente entendidos.
Dependendo das funcionalidades a serem desenvolvidas em cada incremento, atividades de gerenciamento devem realizar o respectivo planejamento, estimação e negociação dos requisitos para cada iteração.
Entretanto, o modelo incremental possui alguns problemas. Algumas funcionalidades dependem de outras, podendo ser interdependentes, por isso pode haver bloqueios no desenvolvimento. Além disso, alterações em requisitos já desenvolvidos invalidam o cronograma e as estimativas.
Modelos evolucionários
Nos modelos evolucionários o software é ajustado, melhorado e agrega novas funcionalidades, tornando-se mais completo, a cada ciclo de desenvolvimento (Pressman, 2006, p. 42). Sistemas de software precisam se adaptar com o passar do tempo. Não há como forçar um desenvolvimento linear até o produto final. A evolução gradual do produto é uma abordagem para solucionar esse problema.
Estes modelos também são iterativos, porém diferem dos modelos incrementais porque acomodam melhor situações onde apenas os requisitos básicos são entendidos, mas os detalhes somente serão conhecidos posteriormente.
Entretanto, nos modelos evolucionários é difícil estimar e planejar a quantidade de iterações necessárias para construir o produto completo, pois a maioria das técnicas de gestão e estimativa de projeto é baseada na disposição linear das atividades (Pressman, 2006, p.47).
A estimação e o planejamento em projetos que adotam o modelo evolucionário devem ser constantemente revisados na medida em que mudanças nos requisitos são detectadas. Na medida em que o projeto evolui, se houver gerenciamento adequado, os ajustes nas estimativas e o replanejamento provavelmente irão convergir para resultados mais próximos da realidade.
Modelos ágeis
O “Manifesto para o Desenvolvimento Ágil de Software” (Agile Manifesto, 2009), assinado no ano de 2001 por alguns proeminentes desenvolvedores de software, deu início um movimento emergente que busca formas de desenvolvimento de software mais ágeis. Este documento enfatiza alguns princípios já conhecidos com o objetivo de superar os desafios modernos do desenvolvimento de software (Pressman, 2006, p. 58).
Os princípios fundamentais dos modelos ágeis são:
- indivíduos e interações em vez de processos e ferramentas;
- softwares funcionando em vez de documentação abrangente;
- colaboração do cliente ao invés de negociação de contratos;
- resposta a modificações em vez de seguir um plano.
Os modelos ágeis procuram estabelecer apenas um conjunto mínimo de organização e disciplina, deixando as demais decisões a cargo da equipe. Há uma suposição de que uma equipe com experiência e diversidade de conhecimentos saberia como coordenar o seu trabalho e se auto-organizar, portanto qualquer tipo de burocracia inibiria a plena capacidade dos indivíduos. Os “agilistas” também defendem a tese que não basta apenas incluir alguns ajustes e boas práticas nos modelos tradicionais, é preciso livrar-se da “roupagem velha”.
O objetivo dos modelos ágeis em geral não é solucionar definitivamente os desafios da Engenharia de Software, mas prover o ambiente mais adequado para o desenvolvimento de software.
Além disso, os defensores e praticantes dos modelos ágeis, chamados “agilistas”, defendem a ideia de que os processos ágeis são os mais adequados para responder às altas taxas de mudanças de requisitos decorrentes da dinâmica dos negócios da atualidade.
Em contrapartida a todos os benefícios dos modelos ágeis, a correta aplicação dos diversos processos ágeis necessita de uma equipe experiente e de indivíduos capacitados e motivados. Além disso, projetos de softwares com alto grau de complexidade exigirão documentação detalhada. Tanto o cliente como os engenheiros de software podem criar barreiras técnicas e pessoais para aceitar o modo de trabalho estabelecido por alguns processos ágeis. Problemas nestes e em outros aspectos podem levar o projeto ao fracasso.
Os modelos ágeis enfatizam que a estimação das histórias de usuário e respectivas tarefas deve ser feita pela equipe de desenvolvimento, pois quem efetivamente executa o trabalho seria mais capacitado a estimá-lo do que pessoas que podem nem estar envolvidas com o projeto. Porém, delegar essa função exigirá organização, experiência e habilidade por parte da equipe. Além disso, os próprios agilistas reconhecem o fato de que desenvolvedores tendem a gerar estimativas otimistas, sendo necessário ao gerente ajustá-las posteriormente (Astels, 2002, p.70).
Em geral, adotar um modelo ágil não implica em restrições quanto à técnica de estimação, desde que a mesma atenda os princípios ágeis. Contudo, técnicas que envolvam a equipe como um todo e enfatizem a comunicação, tal como o Planning Poker (ver capítulo IV), são mais recomendadas.
Modelagem ágil
A modelagem ágil consiste em um conjunto de princípios consistentes com a filosofia dos modelos ágeis de desenvolvimento. Ela não é uma técnica ou método em si, mas estabelece uma filosofia para nortear a modelagem do sistema de software.
Adotar um processo ágil não significa que não haverá documentação, mas que esta deve ser produzida de acordo com os princípios ágeis de desenvolvimento. Ambler (2002) apresenta alguns princípios da modelagem ágil na tabela abaixo.
Tabela 1 – Princípios da Modelagem Ágil (Ambler, 2002)
|
|
|
|
Modelar com uma finalidade
|
Somente criar diagramas, documentação e especificações se houver uma meta específica para isso.
|
|
Usar modelos múltiplos
|
Escolher algumas das múltiplas formas de modelagem existentes que sejam necessárias e representativas.
|
|
Conservar apenas o que for necessário
|
Atualizar os modelos no decorrer do projeto conforme as mudanças nos requisitos gera um trabalho considerável, então somente o que for realmente relevante deve ser conservado.
|
|
O conteúdo é mais importante que a representação
|
A preocupação deve ser em transmitir a ideia e não com os formalismos de um modelo, isto é, as informações contidas nos artefatos devem ser apenas as suficientes para a situação atual.
|
|
Conhecer os modelos e ferramentas
|
Saber como usar corretamente os modelos e ferramentas ajuda na decisão da forma como modelar um problema. Os diversos diagramas possuem características e limitações que são descartados conforme o uso.
|
|
Adaptar localmente
|
A modelagem deve ser adaptada às necessidades do projeto e da equipe.
|
É possível aplicar esses princípios em qualquer modelo de desenvolvimento, mas uma contribuição que os processos ágeis trouxeram foi a ênfase em deixar de usar o “processo pelo processo”, ou seja, usar o processo apenas como um meio para atingir os objetivos da organização e não como um fim em si.
Prototipagem
A prototipagem é uma técnica que pode ser aplicada em modelos iterativos. Ela consiste em produzir uma iteração inicial do software baseada em requisitos de alto nível a fim de testar a viabilidade do projeto e a satisfação do cliente (Pressman, 2006, p. 42). Ela também serve como um mecanismo para identificação dos requisitos, pois permite uma verificação antecipada do que está sendo produzido.
Tudo o que foi produzido deveria ser descartado, pois a construção inicial rápida é geralmente desorganizada e sem qualidade. O custo de corrigir as funcionalidades e a arquitetura de um protótipo pode superar um novo desenvolvimento. A linguagem de programação e as ferramentas de prototipagem podem não ser ideais para o ambiente de produção. Entretanto, a perda pode ser minimizada incluindo o descarte no planejamento.
Existem riscos nesta abordagem. O cliente pode não entender que o protótipo deve ser descartado. Além disso, partes do sistema construídas de forma ineficiente podem permanecer no produto final.
A prototipagem aumenta a qualidade das estimativas quando ela atinge o objetivo de esclarecer os requisitos. Esta técnica é importante quando o domínio é complexo ou há dificuldades de comunicação com os usuários.
Processos de desenvolvimento de software
Modelo Waterfall
O modelo Waterfall é um modelo sequencial (ver Figura 4) de desenvolvimento que, em tese, funcionaria bem quando os requisitos fossem bem conhecidos e poucas mudanças fossem esperadas.
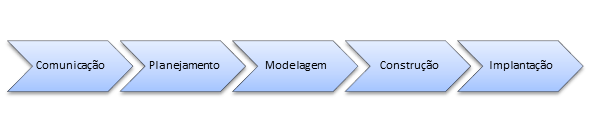
]3 Figura 4 – Adaptado de Pressman (2006, p. 39).
Esse modelo é criticado por apresentar alguns problemas (Pressman, 2006, p. 39). Primeiramente, projetos reais raramente são sequenciais. Ajustes realizados gerariam um tipo de iteração confusa em meio às fases do modelo. Além disso, os requisitos definidos com antecedência sofrerão mudanças difíceis de absorver. Por último, o cliente somente recebe algo executável ao fim do ciclo. Pressman cita o trabalho de Bradac, que verificou que a linearidade deste modelo leva a bloqueios frequentes, ou seja, todos os participantes do projeto precisam esperar todos os demais completarem a fase atual antes de iniciar a próxima fase.
O gerenciamento de um projeto com o modelo Waterfall é mais difícil que em outros modelos. Como o planejamento, que inclui a estimação, é realizada apenas no início, não há muitos pontos de verificação e ajuste. O ajuste das estimativas exigiria atividades de planejamento durante o projeto, o que não é previsto no modelo.
Modelo Spiral
O modelo Spiral é um modelo orientado a riscos cujas iterações iniciais consistem em modelos de papel ou protótipos do software (Pressman, 2006, p. 44). Nas iterações posteriores são produzidas versões do sistema cada vez com mais funcionalidades. Um replanejamento é realizado a cada iteração levando em conta o retorno obtido do cliente.
Esse modelo é um dos mais adaptáveis e gerenciáveis, pois permite absorver com mais facilidade as mudanças nos requisitos de software ao longo do tempo devido à sua natureza iterativa e incremental. Além disso, as iterações podem ser estendidas além da entrega do produto final, incluindo novas versões do produto, finalizando apenas quando o produto for retirado de uso.
Processo Unificado
Segundo Kroll (2003, p. 32), o Processo Unificado é uma abordagem iterativa, centrada na arquitetura e dirigida por casos de uso. Este processo de gerenciamento e desenvolvimento de software foi uma tentativa de combinar as melhores características dos modelos de desenvolvimento (Pressman, 2006, p. 51).
O Processo Unificado enfatiza boas práticas de desenvolvimento (Kroll, 2003, p. 151), o que pode aumentar a qualidade das estimativas. Mitigar os riscos arquiteturais considerados mais impactantes o mais cedo possível através de provas de conceito, por exemplo, ajuda na compreensão do tamanho real do problema. Dessa forma, evita-se a falsa impressão do bom andamento do projeto enquanto os maiores desafios são deixados por último, os quais provavelmente irão invalidar qualquer estimativa. Além disso, se os riscos forem difíceis de superar, o custo de cancelamento do projeto não é tão grande como em fases mais avançadas.
Na verdade, esse processo funciona como um framework que permite a composição de processos específicos. Ele define um conjunto de atividades e produtos de trabalho que podem ser incluídos no processo de uma organização, de acordo com suas necessidades e de seus projetos. As atividades e os produtos de trabalho podem variar em quantidade, tamanho e detalhamento conforme o nível de gerenciamento desejado, além de outros fatores. O grau de burocracia pode ser ajustado de acordo com as necessidades do projeto.
O Processo Unificado pode ser adotado em pequenos e grandes projetos. Kroll (2003, p. 88) descreve aplicações do processo em projeto de apenas uma pessoa até projetos distribuídos com centenas de desenvolvedores, sendo o nível de burocracia em cada tipo de projeto compatível com a necessidade.
Extreme Programming
Beck (1999) publicou um trabalho que deu origem ao Extreme Programming (XP), um processo que utiliza uma abordagem de desenvolvimento orientada a objetos, iterativa e incremental (Novak, 2002). Ele é composto algumas fases que ocorrem a cada iteração (Pressman, 2006, p. 63).
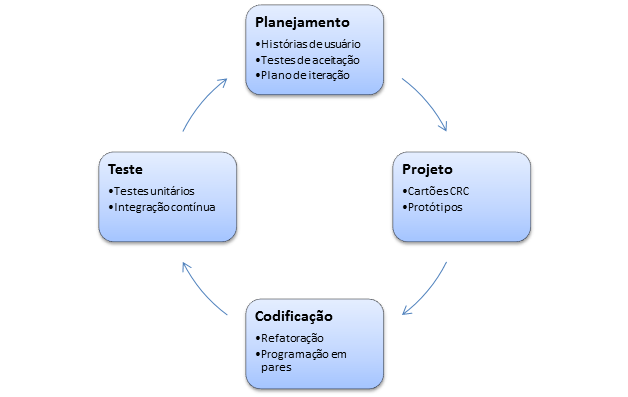
]4 Figura 5 – Adaptado de Presman (2006, p. 64)
Na fase de planejamento cria-se um conjunto de histórias escritas pelo cliente em cartões de indexação, incluindo um valor associado ao negócio. O custo de cada história é definido com base nas avaliações dos desenvolvedores, conforme os princípios do modelo ágil. Algumas histórias são selecionadas para serem desenvolvidas na iteração atual.
A fase de design tem por objetivo criar uma representação simples das histórias que serão desenvolvidas na iteração. Utilizam-se preferencialmente cartões CRC (Classe- Responsabilidade-Colaborador), o único produto de trabalho que faz parte do processo. Cada história de usuário deve ter pelo menos um teste de aceitação para cada cenário identificado. O teste de aceitação de uma história de usuário tem por objetivo demonstrar que o comportamento do sistema corresponde ao esperado pelo usuário.
Durante a fase de codificação, a recomendação é não começar desenvolvendo as funcionalidades do sistema e sim codificando testes unitários para o que será desenvolvido. A codificação é realizada com a recomendação da programação em pares, onde duas pessoas trabalham juntas numa estação de trabalho. O ideal seria que, ao final de cada dia, o código produzido por cada par fosse integrado aos demais na estratégia conhecida como integração contínua.
O Extreme Programming incentiva a refatoração, ou seja, o processo de modificar um sistema de tal modo que ele não altere o comportamento externo do código, mas melhore a qualidade interna do software através de revisões arquiteturais, melhoria de desempenho, alterações no código para aumentar a clareza, entre outros (Astels, 2002, p. 149). É um modo disciplinado de modificar e simplificar o projeto que minimiza as chances de introdução de defeitos. Isso pode ser feito porque os testes automatizados garantem que as funcionalidades do sistema continuem consistentes.
O acompanhamento do progresso de desenvolvimento é realizado através dos testes de aceitação automatizados, embora não se descarte os testes de aceitação do usuário na entrega de uma versão. Dessa forma, o progresso é medido de acordo com uma visão aproximada à que o usuário possui sobre as funcionalidades que ele espera. Isso facilita o alinhamento dos objetivos do usuário com aqueles da equipe de desenvolvimento.
Scrum
O Scrum é um processo ágil de gerenciamento de projetos criado por Jeff Sutherland e Ken Schwaber na década de 90 (Schwaber, 2008). Ele é um processo empírico para desenvolvimento de produtos, isto é, não é restrito ao desenvolvimento de software, podendo ser aplicado em qualquer tipo de projeto cujas características do produto façam com que seu desenvolvimento não seja completamente previsível. Para que seja possível utilizar o Scrum, a equipe deve possuir todas as habilidades necessárias para executar as tarefas do projeto.
O Scrum foi desenvolvido sobre os pilares da transparência, onde os aspectos que afetam os resultados são visíveis para aqueles que gerenciam os resultados, da inspeção, onde os diversos aspectos do processo devem ser inspecionados com uma frequência suficiente para que variações inaceitáveis no processo possam ser detectadas, e da adaptação, pois se um ou mais aspectos do processo estão fora dos limites e o produto resultante for inaceitável, o gerente do projeto deverá ajustar o processo ou o material sendo processado o mais rápido possível para minimizar desvios posteriores.
Esses pilares procuram facilitar o gerenciamento do projeto. Os riscos podem ser mitigados assim que surgem e adaptações realizadas sempre que necessário. A flexibilidade evita que o processo torne-se uma obstrução para que a equipe atenda as necessidades imediatas do negócio.
Existem apenas três papéis que os membros de uma equipe Scrum podem assumir. O Scrum Master é responsável por garantir que o processo seja compreendido e seguido, como um gerente de projeto, o Product Owner por maximizar o valor do trabalho que a equipe desenvolve, representando o cliente, priorizando e explicando as funcionalidades, e o Time é todo o pessoal que executa efetivamente o trabalho.
O Scrum Master é responsável por manter estimativas atualizadas do projeto. As estimativas do projeto como um todo e da iteração atual são parte importante dos pilares acima descritos, pois elas são geradas com base na inspeção, possibilitam a transparência e são base para a adaptação necessária.
O Scrum define apenas quatro produtos de trabalho: o Product Backlog, que consiste em uma lista dos requisitos do produto (histórias de usuário, por exemplo), podendo ser alterado a qualquer momento do projeto; o Burndown da Release, um gráfico que mostra a soma das estimativas de trabalho restantes do Product Backlog ao longo do tempo; o Sprint Backlog, uma lista de tarefas que a equipe deve cumprir para gerar o próximo incremento do produto; e o Burndown da Sprint, um gráfico da quantidade de trabalho restante da iteração atual (sprint).
Os gráficos de burndown fornecem as estimativas atualizadas do projeto. Eles são gerados a partir do backlog e da composição de dados estimados e coletados da velocidade da equipe em cada atividade ou história de usuário. Através desses gráficos o gerente pode responder a qualquer momento sobre o estado da iteração (sprint) e do projeto (release). Porém o gráfico geral do release nem sempre é produzido, pois as histórias de usuário das próximas iterações podem sofrer mudanças drásticas.
As iterações do Scrum são divididas em seis fases, descritas na Tabela 2.
Tabela 2 – Princípios da Modelagem Ágil (Schwaber, 2008)
|
|
|
|
Reunião de planejamento da release
|
Tem o propósito de estabelecer um plano e metas para a iteração que está começando. Nessa reunião o backlog inicial do release é criado.
|
|
Sprint
|
É a iteração em si, que gera um novo incremento do produto contendo a implementação dos requisitos elicitados através das histórias de usuário selecionadas. A indicação da duração é de uma até quatro semanas, dependendo do nível de experiência da equipe.
|
|
Reunião de planejamento do sprint
|
Realização de planejamento da iteração.
|
|
Revisão da sprint
|
O incremento é apresentado aos clientes para obter o feedback e outras informações necessárias ao planejamento do próximo sprint.
|
|
Retrospectiva do sprint
|
A equipe se reúne para analisar as decisões e ações que cada um considera terem sido acertadas ou erradas, por exemplo, sobre ferramentas ou técnicas adotadas, a fim de melhorar o processo de desenvolvimento da equipe.
|
|
Daily Scrum
|
Reunião rápida, com duração média de 15 minutos, onde cada membro da equipe expõe resumidamente o que está fazendo e se há alguma barreira a ser superada.
|
A estimação inicial geral e de cada iteração ocorre nas reuniões de planejamento, enquanto o controle e as atualizações das estimativas são feitos através dos gráficos de burndown.
Combinação de Extreme Programming e Scrum
Por serem processos ágeis, Scrum e a Extreme Programming compartilham de princípios comuns e podem ser usados em conjunto. Scrum é um processo de gerenciamento de projetos, enquanto a Extreme Programming é um processo de desenvolvimento de software. Esses dois tipos de processos geralmente não são excludentes. Kniberg (2006) descreve suas experiências com os processos combinados e afirma que não há conflito entre eles.
Essa combinação é um exemplo de um processo que engloba duas esferas necessárias para o desenvolvimento de um software. Processos de gerenciamento como o Scrum não definem aspectos específicos do desenvolvimento de software, enquanto processos de desenvolvimento como o XP o fazem.
Quando o processo de uma organização não aborda devidamente as áreas necessárias e restam lacunas a serem preenchidas, atividades necessárias podem deixar de ser executadas ou serem feitas empiricamente, de forma marginal ao processo e sem gerenciamento.
Test Driven Development
O Test Driven Development (TDD) é um processo de desenvolvimento de software orientado por casos de testes. A partir dos cenários de uso identificados para um sistema, codificam-se testes para cada um deles. Durante o desenvolvimento, escreve-se o código necessário para obter sucesso em cada teste. Por fim, melhora-se a arquitetura e o código em geral usando os testes para garantir que o funcionamento esperado não foi afetado (Koskela, 2008, p. 33).
Este processo procura alinhar o desenvolvimento com os requisitos de negócio através dos testes de aceitação, garantindo que o software atenderá as necessidades de negócio. Se os testes de aceitação refletem o comportamento esperado pelos usuários, então o critério de avaliação do software é o resultado da execução dos testes. Isso permite avaliar e acompanhar a qualidade do sistema de um ponto de vista semelhante ao do usuário, evitando que sejam empreendidos esforços em não conformidade com as necessidades de negócio.
O TDD pode melhorar a acurácia da estimação. Ela procura garantir que a equipe tenha o entendimento das funcionalidades através da criação precoce dos testes. Assim, como a equipe precisa que conhecer os requisitos para a criação dos testes, ela terá uma noção mais apurada do problema, o que pode levar a estimativas melhores.
Feature Driven Development
O Feature Driven Development (FDD) é um processo prático, iterativo e incremental de desenvolvimento de software orientado a objetos com foco nas características do sistema. Uma característica “é uma função valorizada pelo cliente que pode ser implementada em duas semanas ou menos” (Pressman, 2009, p. 71). A cada iteração de incremento do software algumas características que agregam valor ao produto são estimadas, selecionadas e então desenvolvidas de forma que o resultado do respectivo teste passe a ser de sucesso.
O objetivo deste processo é valorizar o produto focando as características que o cliente necessita. O foco em características facilita a compreensão do produto pelo cliente e no entendimento deste com a equipe de desenvolvimento.
O FDD pode dificultar a atividade de estimação quando as características são muito abstratas em relação ao software. A visão do produto através de características pode ser mais compreensível do ponto de vista do usuário, mas para a equipe de desenvolvimento é um desafio tentar prever o esforço de desenvolvimento necessário para uma característica descrita em alto nível.
Conclusão
Conhecer e entender os diferentes modelos e processos de desenvolvimento de software e gerenciamento de projetos é importante para uma estimação adequada. Os processos e modelos fornecem abordagens práticas para o desafio de desenvolver software de acordo com as reais necessidades do cliente.
Há uma tendência dos processos modernos em buscar flexibilidade, menor burocracia e manter o foco no produto de negócio. Isso significa diminuir o tempo que a equipe gasta com atividades desnecessárias ou sem sentido de modo a não encarecer o produto e tornar possível que a organização coloque seu foco no negócio e não em processos, técnicas ou tecnologias.
O próximo capítulo apresenta noções de estimativas, além de técnicas e modelos de estimação. As práticas e abordagens dos processos de software apresentadas neste capítulo e as noções de engenharia de requisitos apresentadas no capítulo anterior fornecerão uma base para a correta compreensão da atividade de estimação e de sua execução dentro dos processos de desenvolvimento.









