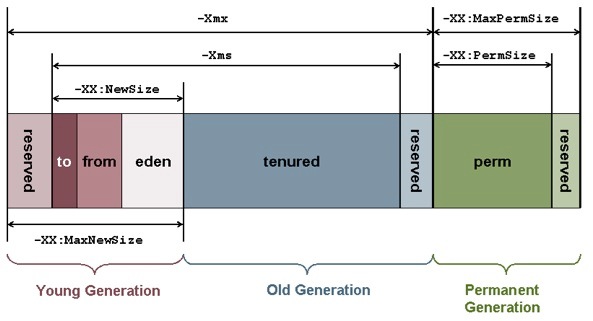
Este artigo é a conclusão da minha monografia de Especialização em Engenharia de Software. Espero que o possa ser útil de alguma forma para o leitor.
Introdução
Este capítulo apresenta as conclusões com base nos tópicos discutidos neste trabalho, relaciona possíveis trabalhos futuros que poderiam estender esta pesquisa e avalia a principal contribuição da mesma.
Conclusões
O primeiro capítulo estabeleceu algumas bases teóricas sobre o desenvolvimento de software com base na Engenharia de Software, uma disciplina que trata dos aspectos do desenvolvimento de software e provê abordagens para que o desenvolvimento atinja os objetivos do negócio.
O software não é fabricado em série como um produto “tradicional”, ele é desenvolvido. Tomando como exemplo um modelo de automóvel, o processo de fabricação do mesmo é definido linearmente do início ao fim. Ao invés disso, o desenvolvimento de software pode ser comparado ao projeto de criação do modelo do automóvel, o que ocorre antes da fabricação em série.
A arquitetura de um software é importante para a estimação, pois ela determina os tipos de componentes que irão compor o software e os relacionamentos entre eles, afetando diretamente a complexidade e as regras de desenvolvimento.
Existem barreiras no desenvolvimento e dificuldades intrínsecas na estimação de software. Algumas delas tem sua origem em características do software como intangibilidade, complexidade e mutabilidade. Outras são oriundas de fatores humanos, como a dualidade de visão entre desenvolvedores, que pensam em nível funcional, e gerentes, que muitas vezes são orientados a cronograma e custos.
O segundo capítulo apresentou noções sobre Engenharia de Requisitos, uma atividade que busca o entendimento do software a ser construído e o gerenciamento das mudanças no decorrer do desenvolvimento.
Requisitos podem ser representados em vários níveis de detalhamento, mas para o desenvolvimento de software é necessário que eles sejam definições matematicamente formais das funcionalidades do software. Requisitos não existem por si só, isto é, eles não são levantados, encontrados ou identificados, mas são elicitados e definidos por um analista.
Requisitos são fundamentais para a estimação, pois fornecem a abstração necessária do problema para que os engenheiros de software cheguem ao modelo da solução que represente o instantâneo dos requisitos num determinado momento.
Estimativas são derivadas do modelo de análise e design. Estes modelos representam uma abstração da solução a ser desenvolvida em forma de software.
Ainda que algumas abordagens de estimação não incluam um modelo formal, os estimadores acabam usando um modelo de análise implícito em suas mentes, pois para chegar a uma estimativa de desenvolvimento eles precisam mentalizar a arquitetura e os componentes a serem desenvolvidos.
Os requisitos mudam ao longo do tempo por definição. O software é construído com base num modelo que representa os requisitos elicitados num determinado momento.
As mudanças nos requisitos devem ser gerenciadas para que seja possível identificar o impacto no software. A análise de impacto pode se beneficiar da rastreabilidade, isto é, uma relação entre os componentes do software que permita identificar quais deles devem ser modificados para atender uma mudança de requisito. Neste ponto, a arquitetura exerce um papel fundamental ao estabelecer a forma de organização e comunicação entre os componentes.
A qualidade da estimação no decorrer do desenvolvimento depende do gerenciamento de mudança dos requisitos, da qualidade da arquitetura e da rastreabilidade para que o estimador tenha consciência das alterações que são necessárias no software. Sem isso, é provável que o desenvolvimento siga sem um horizonte visível.
O terceiro capítulo discorreu sobre processos de desenvolvimento e gerenciamento de software. Processos são fundamentais para organizar o desenvolvimento de software e evitar o caos. Todo desenvolvimento segue um processo, seja ele bem definido, informal ou empírico.
Os modelos de processo propostos pela Engenharia de Software são abstrações de processos que as organizações podem implementar em seus projetos.
Alguns processos focam mais o gerenciamento do projeto, enquanto outros o desenvolvimento do software. Por isso, processos podem ser usados de forma complementar em um projeto de desenvolvimento de software.
Os processos podem ser classificados de acordo com a burocracia ou disciplina exigida. Processos burocráticos facilitam o gerenciamento, mas acrescentam uma carga adicional aos envolvidos no projeto. Processos empíricos, como os processos ágeis, procuram eliminar essa carga, baseando-se na confiança e interação entre a equipe ao invés da formalização.
A estimação de software deve considerar o processo adotado. Estimativas devem ser ajustadas de acordo com as atividades definidas e os produtos de trabalho exigidos pelo processo vigente, pois estes elementos impactam na produtividade da equipe. Além disso, estimativas de prazo e cronograma podem ser ajustadas e atualizadas de acordo com a iteratividade do processo e do modo como as funcionalidades são implementadas, isto é, num modelo evolucionário ou incremental.
Os processos ágeis introduziram uma séria de conceitos ao desenvolvimento de software procurando ser bastante adaptáveis às mudanças de requisitos, minimizar o tempo de resposta a estas mudanças e, dessa forma, atender as necessidades mais imediatas dos clientes. Para atingir esses objetivos, o processo é reduzido a um mínimo de disciplina e organização e espera-se que a equipe de desenvolvimento esteja motivada e se auto-organize para atender as necessidades imediatas do projeto.
Na prática, várias atribuições do gerente do projeto recaem sobre a equipe de desenvolvimento. Quando esta equipe possui maturidade e habilidade suficiente para arcar com essas responsabilidades, o que inclui planejar e estimar suas próprias tarefas, o processo ágil realmente pode otimizar o desenvolvimento software. Em contrapartida, o desenvolvimento pode chegar ao caos se os indivíduos envolvidos não corresponderem a estas expectativas.
Em decorrência disso, mesmo os “agilistas” às vezes utilizam certas práticas contrárias ao modelo ágil, como em casos onde o responsável pelo projeto ajusta as estimativas da equipe.
O quarto capítulo apresentou noções de estimação de software e algumas das técnicas comumente utilizadas em processos tradicionais e ágeis.
Estimativas são importantes do ponto de vista gerencial, pois clientes e gerentes precisam ter um horizonte sobre o desenvolvimento de um software.
O objetivo da estimação não é simplesmente fornecer uma data de entrega, mas possibilitar decisões corretas de negócio para que os objetivos da organização sejam atingidos ou ainda a correta avaliação desses objetivos para averiguar se eles são realmente tangíveis.
Estimativas não devem ser precisas, ou seja, utilizar uma unidade de medida pequena ou casas decimais, elas precisam ter acurácia, que significa estar próximo à realidade.
Embora estimativas geralmente sejam representadas numericamente, elas representam uma ordem de grandeza e não valores reais e absolutos. Manipular matematicamente os números das estimativas é um erro e leva à falsa sensação acurácia. Por exemplo, dobrar a quantidade de programadores não diminui pela metade o tempo de codificação. Esta e outras armadilhas são evitadas quando se entende a natureza real da estimação, que não consiste em medir algo, mas tentar prever sua ordem de grandeza.
Além disso, uma estimativa não deve ser confundida com o compromisso da equipe de desenvolvimento em concluir o trabalho num determinado prazo, tampouco com o plano da organização para atingir uma meta. É um erro grave manipular estimativas para adequá-las a uma determinada agenda. Cabe ao gerente do projeto usar as estimativas para calcular os recursos necessários para cumprir um plano ou então negociar os prazos do projeto.
Estimativas possuem um grau de incerteza. No de correr do projeto, quanto mais cedo a estimação for realizada, maior a incerteza. Em teoria, à medida que o desenvolvimento evolui, a incerteza diminui proporcionalmente ao conhecimento mais detalhado sobre o problema e a solução. Entretanto, isto somente será a realidade se houver o gerenciamento adequado, caso contrário o desenvolvimento pode acabar num ciclo interminável de correções e mudanças.
Bons estimadores devem considerar influências externas sobre o projeto e o software. Isto inclui fatores humanos, do ambiente do projeto, políticos e técnicos. Certas características do projeto também devem ser levadas em conta, como o tamanho do projeto, tipo de software, experiência da equipe e restrições tecnológicas.
Além disso, a qualidade da estimação é afetada por diversos fatores, tais como falha na elicitação de requisitos, falta de experiência da equipe, atividades omitidas, otimismo sem fundamento dos desenvolvedores e tendências pessoais do estimador.
Embora muitas variáveis influenciem na estimação, não é recomendável investir esforço demasiado nesta atividade, assim como se deve evitar exagero de detalhes. Diversos autores verificaram que, a partir de um determinado ponto, esforços e detalhes adicionais desviam as estimativas da realidade.
O mesmo princípio é aplicado à precisão desnecessária. Estimar um projeto de vários meses em horas de trabalho, embora seja uma unidade precisa, passa uma falsa sensação de acurácia. Neste caso, seria melhor adotar uma unidade de dias ou semanas de trabalho.
Diferentes técnicas de estimação foram apresentadas. Em geral, elas consistem em contar e julgar os elementos da solução proposta, em seguida aplicar uma fórmula prescrita e, finalmente, calibrar os resultados obtidos através de dados históricos e da avaliação das influências externas e características do projeto. A arquitetura do software é importante para a identificação e classificação dos elementos do sistema.
Algumas técnicas de estimação utilizam elementos do problema ao invés da solução, tal como o Planning Poker. Neste caso, o estimador acaba por construir mentalmente a ponte de ligação entre as necessidades dos clientes e da solução proposta, isto é, o modelo de análise e design.
Outras técnicas, como o Function Point, utilizam elementos pré-definidos que não levam em consideração a arquitetura do software. Técnicas deste tipo podem levar a desvios na estimação, pois nem sempre um software pode ser representado adequadamente no modelo exigido pela técnica.
A qualidade da estimação depende diretamente da habilidade, do conhecimento e da experiência do estimador. Em geral, o gerente do projeto é responsável pela estimação. Ele pode delegar esta atividade como um todo ou em parte para um ou mais membros da equipe, como nos processos ágeis. Porém, é necessário avaliar se as pessoas envolvidas estão capacitadas, afinal, é um consenso que desenvolvedores em geral são muito otimistas quando fornecem estimativas.
Alguns autores consideram a estimação como uma arte, outros como um processo de engenharia. Ambos contam com certa razão, pois tanto um bom artista como um bom engenheiro precisam de treino, técnica e habilidade para exercer seus talentos com perfeição. Além disso, o próprio desenvolvimento do software é considerado por alguns como um processo artesanal. No entanto, embora o talento dos indivíduos seja um elemento importante no desenvolvimento e na estimação, o conhecimento e o uso de técnicas adequadas irá potencializar esse talento.
Este estudo pretendia incluir uma comparação entre as técnicas de estimação com a finalidade de identificar as melhores técnicas disponíveis. Mas estimativas são previsões. Não há como comparar objetivamente técnicas que procuram antecipar o futuro.
A escolha da técnica de estimação em um projeto depende do que o estimador considerar conveniente. Assim, este estudo buscou trazer conhecimentos essenciais sobre estimação e os elementos que mais o influenciam para que o estimador tenha uma visão mais ampla sobre esta atividade e tome decisões conscientes.
O estimador deve conhecer o processo de desenvolvimento o mais detalhadamente e abrangentemente possível, ser realista e sincero quanto ao tempo de cada atividade e saber negociar os prazos com a área de negócios, que sempre exigirá entregas antecipadas.
Trabalhos Futuros
Como base teórica, o presente estudo limitou-se a apresentar conceitos sobre aplicativos de software, engenharia de requisitos, processos de desenvolvimento e gerenciamento de software que influenciam na estimação de software. Além disso, conceitos de estimação e diversas técnicas foram apresentados, concluindo com um estudo de caso com a aplicação de uma delas.
Outros trabalhos podem ser realizados comparando como as técnicas de estimação se encaixam nos diversos processos existentes. Algumas técnicas necessitam de determinados modelos que não são recomendados em processos ágeis, por exemplo. Por outro lado, o Planning Poker pode ser de difícil de execução quando requisitos formais estão especificados e não há estórias de usuário.
Outra possibilidade de estudo complementar seria analisar a usabilidade das técnicas de estimação, ou seja, verificar na prática se as técnicas são usadas corretamente ou se elas podem levar a armadilhas. Uma técnica pode se apresentar boa em teoria, mas a falha em entender a técnica pode levar a estimativas equivocadas.
Além disso, uma análise mais detalhada das técnicas usadas em processos ágeis poderia ser útil para verificar se essas técnicas trazem algum benefício em relação às técnicas mais tradicionais. Poderia-se analisar como esses métodos percorrem a distância entre o problema a solução para fazer a estimação ou ainda analisar as contradições e os pontos em que os “agilistas” discordam entre si.