Muitos desenvolvedores enfrentam grandes dificuldades em trabalhar com JPA (Java Persistence API). Vejo que a maioria dessas dificuldades tem raiz na falta de compreensão de certos detalhes do funcionamento do JPA.
Analisarei neste artigo um caso que gera muita confusão, que é o uso do método merge().
JPA?
Antes de mais nada, para quem não conhece a tecnologia, JPA é uma API ou um padrão de persistência de dados através de mapeamento de objetos e tabelas, isto é, mapeamento objeto-relacional (ORM – Object Relational Mapping).
O problema é que não existe um meio de realizar esse mapeamento entre objetos e tabelas que seja 100% transparente, pois o paradigma de armazenamento de dados relacionais implementado pelos SGBDR’s (Sistemas Gerenciadores de Bancos de Dados Relacionais) é incompatível com o paradigma de orientação a objetos.
Sendo JPA uma API, para efetivamente usá-lo é necessário adotar uma das implementações disponíveis, sendo as mais comuns o Hibernate e Eclipselink.
Objeto vs. Entidade
Ao trabalharmos com JPA é importante ter em mente que um objeto qualquer, mesmo sendo instância de uma classe anotada com @Entity ou mapeada em algum XML, não é automaticamente uma entidade JPA.
Isso significa que não importa se a PK ou os campos está devidamente preenchida, um objeto não é uma entidade se não está gerenciado num contexto de persistência (persistence context).
Estados de uma entidade JPA
Vejamos um diagrama de estados simplificado do JPA (fonte):
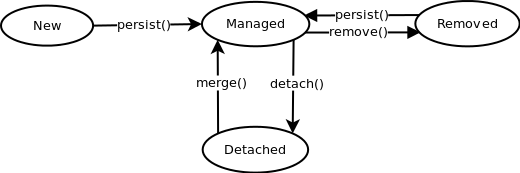
Diagrama de estados JPA
Quanto criamos uma instância do objeto ele está no estado novo (new). Ao chamarmos o método persist nosso objeto passa a ser uma entidade gerenciada (managed), embora o registro provavelmente não seja inserido no banco de dados até o commit.
Após o encerramento do context do JPA (commit da transação, close do EntityManager ou método detach), nossa entidade entrará no estado detached. Posteriormente poderemos trazê-la novamente para o contexto de persistência do JPA com o método merge.
Se excluirmos uma entidade com o método remove ela entrará no estado removida (removed) e até o fim da transação um comando DELETE será enviado ao banco de dados. Se quisermos persistir a entidade novamente, podemos chamar o método persist.
Como funciona o merge
Agora que entendemos os estados das entidades, vejamos agora como funciona o método merge. Eis um diagrama muito interessante (fonte):

Fluxograma do Merge
- O primeiro passo do
mergeé verificar se a entidade está no estado gerenciado (managed), pois em caso afirmativo a própria entidade é retornada. - Se a entidade foi removida (removed) um erro é lançado.
- Se o contexto de persistência já possui uma versão dessa entidade, ela será atualizada com o estado do objeto passado por parâmetro e então será retornada.
- Se não há uma entidade equivalente, verifica-se se esta é uma nova entidade:
- Se for, cria-se uma nova instância (equivalente ao
persist). - Se não for, carrega-se a entidade no contexto de persistência a partir do banco de dados.
- Se for, cria-se uma nova instância (equivalente ao
Um erro comum ao usar merge
Note que o principal objetivo do método merge é devolver uma entidade JPA gerenciada pelo contexto de persistência e atualizada com os valores do objeto recebido.
Se o objeto passado como argumento não for uma entidade JPA, o mesmo não será incluído no contexto de persistência, mas uma cópia será feita e retornada pelo método merge.
Como descrito nesta famosa questão do SO, um erro comum é esperar que o objeto passado para o método torne-se uma entidade.
Uso incorreto:
MyEntity e = new MyEntity();
em.merge(e);
e.setAtributo(novoValor);
No exemplo acima, alterar o valor do objeto original não afeta o estado da entidade JPA criada pelo merge.
Uso correto:
MyEntity e = new MyEntity();
MyEntity e2 = em.merge(e);
e2.setAtributo(novoValor);
Já neste exemplo, o valor será atualizado no banco de dados pois a entidade gerenciada retornada pelo merge foi modificada.
Quando o merge gera novos registros
O método merge irá incluir uma nova entidade e, consequentemente, um novo registro no banco de dados, quando o objeto passado para o método for considerado uma nova entidade.
Em quais cenários isto é possível? Não posso prever todos, mas eis os mais comuns:
- A PK é um valor sequencial (
@GeneratedValue) e não está devidamente preenchida, gerando assim uma nova entrada no banco de dados. - Há uma coluna de versão (
@Version) que não está devidamente preenchida no banco de dados (ver esta questão). - Existe um relacionamento com outra entidade e, por alguma razão, o JPA está gerando uma query com
INNER JOINentre as duas tabelas e não encontra resultados devido à ausência de registros na outra tabela, chegando à conclusão de que a entidade principal não existe. Este artigo trata do assunto com relação a uma anotação do EclipseLink, mas isso pode ocorrer no Hibernate de algumas formas, por exemplo, via herança.
Atualizando atributos específicos de entidades
O problema do merge é que todos os atributos da entidade são sobrescritos com os valores do objeto recebido.
Considere o exemplo:
MyEntity e = //entidade criada em algum outro lugar (JSF, Spring, etc.)
em.merge(e);
No código acima, corre-se o risco de sobrescrever algum valor campo da entidade que não queremos. Para não incorrer nesse problema, em muitos casos é melhor recuperar a entidade armazenada e então atributos os novos valores individualmente.
Exemplo:
MyEntity recebida = //entidade criada em algum outro lugar (JSF, Spring, etc.)
MyEntity original = em.find(MyEntity.class, recebida.getId());
original.setAtributo(recebida.getAtributo());
Embora atualizar os atributos individualmente seja mais trabalhoso e faça o código ficar maior, isto evita que a “mágica” dos frameworks ou mesmo a manipulação indevida de atributos acabe gerando efeitos não esperados no banco de dados, algo, infelizmente, muito comum e um verdadeira risco à segurança.
Quando usar merge, find e getReference
Outro dúvida como é sobre como e quando usar esses métodos e como eles funcionam.
Como funciona o getReference()
O getReference() retorna um proxy para uma entidade que está no banco de dados. Os dados não são carregados do banco imediatamente, a não ser a chave primária. Esse proxy funciona como um objeto lazy que só vai carregar os atributos da entidade quando você chamar algum método getter.
Enfim, use esse método quando você quer evitar carregar muitos dados do banco desnecessariamente, como em casos em que você vai usar apenas um ou dois campos de uma entidade apenas se uma determinada condição for satisfeita ou quando você precisar passar uma entidade como parâmetro e possivelmente ela não é usada dentro do método receptor.
Enfim, a vantagem é postergar a transferência de dados que você provavelmente não vai usar. A desvantagem é que, se for usar os dados, o “custo” é maior já que vai ter que fazer mais consultas ao banco.
Sinceramente, nunca vi necessidade real do uso desse método.
Como funciona o find()
O método find() também retorna uma entidade pela chave primária, porém já com os dados carregados, exceto é claro relacionamentos lazy.
Considerações
Para recuperar uma entidade, o método find() quase sempre é o que você vai precisar. Use o find() por padrão e, se tiver problemas de desempenho, então verifique qual outro método pode ajudar.
Para atualizar uma entidade, use o merge() quando você já tem um objeto populado com todos os novos valores que seja gravar no banco.
Para atualizações parciais, use o find() ou getReference() e o respectivo setter da propriedade que deseja atualizar.
Este artigo foi baseado em duas respostas que publiquei no Stack Overflow em Português