Este artigo é o Capítulo I da minha monografia de Especialização em Engenharia de Software. Embora seja um referencial teórico e não acrescente nada de novo, espero que o possa ser útil de alguma forma para o leitor.
Introdução
Neste capítulo são apresentadas definições de termos utilizados neste estudo com o intuito de nivelar o entendimento sobre os mesmos. Embora tais conceitos possam ser considerados de senso comum, é certo que existem visões distintas e conflitantes.
Os próximos tópicos revisarão alguns conceitos da Engenharia de Software pertinentes ao tema.
Definição de aplicativo de software
Aplicativos de software são “programas isolados que resolvem uma necessidade específica do negócio” (Pressman, 2006, p. 4). Exemplos disso são softwares que processam dados comerciais ou técnicos que facilitam as operações e a gestão de um negócio. Além do código-fonte, o software inclui toda a documentação e os dados necessários para que o programa funcione corretamente (Sommerville, 2003, p. 5).
Definição de Engenharia de Software
A Engenharia de Software é a disciplina que trata de todos os aspectos do desenvolvimento de um software, incluindo as atividades de engenharia de requisitos, os modelos de processos e os modelos e técnicas de estimação (Sommerville, 2003, p. 6-7).
Um aplicativo de software é desenvolvido através de um processo. Não é algo que se fabrica a partir de matéria prima, nem é montado a partir de partes menores. Segundo Pressman (2006, p. 4), o software apresenta esta característica especial em relação a outros tipos de produtos, ou seja: ele não é fabricado no sentido clássico, mas desenvolvido, passando por um processo de engenharia.
A Engenharia de Software fornece abordagens sólidas para aumentar as chances de que os objetivos de negócio sejam atingidos em termos de prazo, qualidade e funcionalidades. Segundo Campos (2009, p. 2), as organizações enfrentam hoje o desafio de desempenhar suas atividades de forma produtiva, com qualidade e cumprindo o planejamento estratégico. Portanto, o uso de uma abordagem adequada no desenvolvimento de um software para elicitação de requisitos, estimação, desenvolvimento e controle é fundamental para as organizações.
Definição de projeto de software
Um projeto consiste num empreendimento temporário, cujo objetivo é a criação de um produto ou prestação de um serviço. Um projeto de software consiste no desenvolvimento de um software, incluindo os artefatos relacionados.
Independente do modelo de processo adotado, o empreendimento de construção de um software envolve atividades de diversas áreas de conhecimento utilizadas em maior ou menor grau durante as fases do projeto, nos âmbitos de gerenciamento e desenvolvimento.
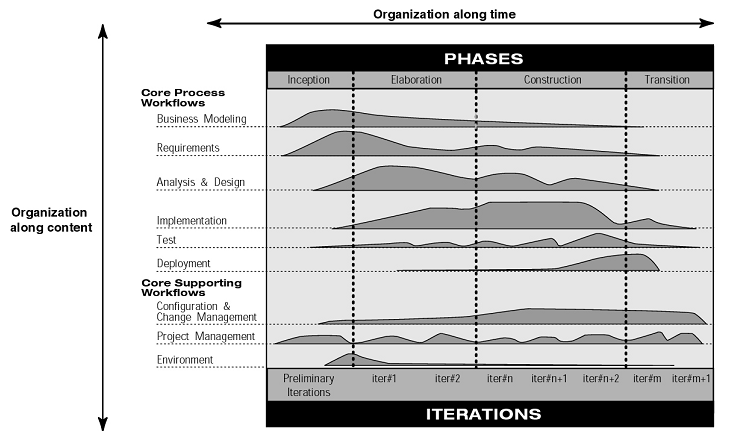
Figura 1 – Visão geral de um modelo iterativo (Rational, 2001)
O Processo Unificado (Rational, 2001), por exemplo, classifica as atividades da Engenharia de Software em nove disciplinas, dentre as quais cinco são relacionadas diretamente ao produto de software e três ao controle e gerenciamento, isto é, atividades de suporte ao desenvolvimento (Figura 1). No decorrer do projeto, as disciplinas demonstram um maior ou menor grau de atividade e nota-se que o gerenciamento do projeto é a única disciplina utilizada com certa regularidade no decorrer do tempo.
As estimativas de software são o fundamento para o planejamento do projeto ao permitirem uma visão geral do esforço necessário para o desenvolvimento e de variáveis que influenciam o projeto positivamente ou negativamente, tais como a produtividade da equipe e a complexidade do domínio.
Noções sobre arquitetura de software
Antes do desenvolvimento de um software é necessário definir sua arquitetura. O projeto da arquitetura é realizado através da decomposição do software em componentes. A arquitetura descreve o papel dos componentes que compõem o software e o relacionamento eles (Sommerville, 2003, p. 182).
A arquitetura do software fornece um framework estrutural básico para o desenvolvimento do software. Os diversos componentes do sistema agrupam elementos similares, tal como objetos com comportamento semelhante, e facilitam a estruturação do software. Dessa forma, é possível determinar com facilidade quais partes do sistema são afetadas pela implementação ou alteração de uma funcionalidade, pois os tipos de componentes e objetos estarão previamente definidos.
A decomposição arquitetural fornece um ponto de partida para técnicas de estimação baseadas em objetos ou elementos do software. A estimação é possível ao contar os elementos de um componente e estimar cada componente dessa forma. A estimativa resultante tende a ter mais qualidade devido ao conhecimento do tipo de elemento do componente em relação a estimativas geradas sem uma arquitetura definida.
Além disso, a arquitetura influencia diretamente na complexidade do software (Pressman, 2006, p. 223). Quanto mais dependências compartilhadas de recursos, tal como banco de dados ou arquivos, e dependências entre os componentes que compõem o software, maior será a sua complexidade. Um grande número de interdependências faz com que qualquer alteração cause maiores impactos em outros componentes.
Através da arquitetura é possível analisar o impacto de modificações no software. Isso é feito considerando as dependências entre os componentes. Além disso, ao desenvolver uma nova funcionalidade, é mais fácil identificar com antecedência os elementos dos componentes que serão necessários desenvolver, modificar ou reusar.
A análise de impacto de alterações é importante para o ajuste das estimativas dos componentes afetados quando se deseja obter uma posição atualizada do projeto.
Barreiras do desenvolvimento e estimação de software
A atividade de estimação consiste em tentar antecipar o tamanho ou esforço de desenvolvimento de um produto abstrato. Existe uma série de desafios que fazem com que o software seja difícil de estimar e, consequentemente, o projeto difícil de planejar.
Por um lado, isso se deve a características intrínsecas ao software. Brooks (1987) afirma que, por definição, o software é complexo e irredutível, ou seja, não é possível simplificá-lo sem que haja perda de informação. Ele apresenta quatro características importantes que contribuem para isso, tornando o software essencialmente difícil de construir:
- Complexidade: entidades de software são extremamente complexas para seu tamanho e não existem duas partes iguais no nível de algoritmo. Isso faz parte da natureza do software, não ocorrendo por acaso. A escalabilidade de um software, por exemplo, não consiste simplesmente em fazer suas partes maiores ou menores, diferentemente de construções físicas realizadas pelo homem.
- Conformidade: apesar de existirem áreas onde pessoas lidam com alta complexidade, o software possui algumas complicações adicionais. Por exemplo, um físico lida com a complexidade do átomo, mas este possui uma interface “bem definida” pela natureza, ou seja, os átomos possuem uma conformidade. O software tem diversas interfaces diferentes definidas por diversas pessoas e geralmente há pouca ou nenhuma conformidade nestas definições.
- Mutabilidade: o software parece estar sempre pressionado a mudar. Produtos fabricados como pontes, carros e máquinas também estão, mas geralmente eles são substituídos por novos modelos, não sendo modificados com a mesma facilidade de um software. Eles são produtos tangíveis, com escopo bem definido e o custo de modificações maiores é impeditivo. Um software, por ser abstrato e com baixos custos diretos para se mexer, muitas vezes sem aparentes consequências imediatas, sofre constantes mudanças. Além disso, a maioria das mudanças tem como objetivo fazer com que o software vá além de seus limites iniciais.
- Invisibilidade ou intangibilidade: apesar de existirem interfaces e linguagens amigáveis, o software não pode ser visualizado através de imagens. Em geral, desenvolvedor e usuário não conseguem enxergar o software como um todo. Isso ocorre porque os usuários geralmente não compreendem as questões tecnológicas e os desenvolvedores não entendem todas as regras do negócio, além do que um software pode ser desenvolvido por diversos indivíduos especialistas em diferentes áreas. Portanto, como cliente e desenvolvedor não conseguem ter em mente o software por completo, as chances de erros aumentam.
A estimação é realizada com base numa abstração em forma de requisitos. Por definição, ela não pode ser exata ao considerar as características apresentadas acima, pois a estimativa é, na verdade, baseada numa ideia pré-concebida do software.
Mesmo medidas do produto final de software são subjetivas. Não existem métricas objetivas de tamanho, qualidade, eficiência, robustez, usabilidade e tantos outros aspectos. Mesmo o número de linhas de código ou caracteres do código fonte não possuem uma relação direta com as funcionalidades e características do software, embora muito esforço tenha sido empreendido em conseguir uma aproximação razoável. Isso implica em que qualquer comparação entre softwares, processos de desenvolvimento, técnicas estimação e de engenharia de requisitos somente podem ser realizadas através de critérios específicos e objetivos. Portanto, não é possível afirmar categoricamente que uma técnica, método ou modelo seja superior a qualquer outro.
Por outro lado, o fator humano acrescenta ainda mais dificuldades no desenvolvimento e na estimação de um software. Enquanto desenvolvedores e arquitetos pensam em nível técnico e funcional, os gerentes observam o cronograma e os custos. Não é tarefa fácil conciliar ambas as perspectivas, sendo um desafio alinhar os objetivos estratégicos de uma organização com os aspectos técnicos e abstratos de um produto de software.
Do ponto de vista de quem está gerenciando o projeto, prazo e cronograma são fundamentais para que decisões sejam tomadas e estratégias de negócio estabelecidas, portanto boas estimativas são necessárias. Isso pode ser um problema do ponto de vista da equipe de desenvolvimento, por exemplo, quando prazos arbitrários são definidos ou tempo e recursos disponíveis são tecnicamente insuficientes.
Portanto, tanto a natureza do software quanto os fatores humanos devem ser considerados na estimação. Da mesma forma, quando há alterações no contexto do projeto de software, tal como mudança nos requisitos, no domínio ou na equipe, as estimativas são afetadas e devem ser ajustadas.
Conclusão
Este capítulo definiu o tipo e a natureza da entidade de software, além de descrever brevemente alguns aspectos relacionados ao processo de desenvolvimento.
Sistemas de software são entidades complexas e difíceis de desenvolver. Por isso, a Engenharia de Software busca mitigar os riscos e diminuir as falhas em projetos de desenvolvimento software através de modelos de processos, técnicas e boas práticas.
Entretanto, a correta estimação de um software inclui compreender o que exatamente deve ser construído e como isso será realizado. Assim, os próximos capítulos apresentam abordagens da Engenharia de Software para a engenharia de requisitos e para o desenvolvimento e gerenciamento do projeto.